Эта история приключилась в конце декабря 2017 года, в его последние дни. Пока люди сражались за еду, отвоёвывая последние лотки яиц на витринах супермаркетов, отходили от похмелья после последней пятницы уходящего года, я никак не мог войти в праздничное настроение. Всему виной был проблемный предновогодний релиз. Над поиском причины я возился уже несколько дней, но не видел зацепок. 29 числа я уже смирился, что поиск будет длительным и сложным, и продолжу я его уже в 2018 году, но с самого утра 30 декабря в голову снова начали лезть мысли…
История призвана послужить гайдлайном при решении задач. Я постарался максимально подробно описать ход своих мыслей и вектор поиска решения. Но начну историю с описания самого релиза. На протяжении почти двух лет мы жили с видеостриминговой подсистемой, которую сдали нам в эксплуатацию аутсорсеры. На этапе приёмки не было достаточной экспертизы, что и послужило мотивацией к заказу аутсорс услуг, а в ходе эксплуатации были обнаружены критические недоработки. Вообще, решение оказалось наколеночным и ни разу не enterprise. Аутсорсеры как-то туго решали проблемы, даже с наличием платной поддержки. Складывалось впечаление, что там только один адекватный человек в команде, и тот вечно задерганый. Я и команда пытались решить проблемы в рамках уже существующего решения, но стоимость зашкаливала. Те, кто сталкивался с live streaming, наверняка представляют, какой гемор перепиливать сишный транскодер на базе libx264, когда нарушена логика работы с time frames, CBR просто не обеспечить, а, чтобы прикрутить нарезку HLS, нужно сесть на шпагат на два стула, промеж которых пики точеные…
Так и родилось волевое решение выкинуть вот это вот всё и написать правильно и красиво. В создании правильного и красивого команда провела 7 месяцев… Я же взял на себя обязательства выкатить эти глобальные изменения в 2017 году, в декабре. Обещания нужно держать, а когда вроде как всё проверили и всё было окей, то зарелизились. За 13 дней до НГ.
UPD! Доступно видео с Fwdays Highload 2019. Можно смотреть его, а затем углубляться в детали в тексте.
Пока были заняты миграциями и проверкой корректности организационной части, то первый партнёр-пользователь системы заметил, что количество ошибок html5 плеера выросло.
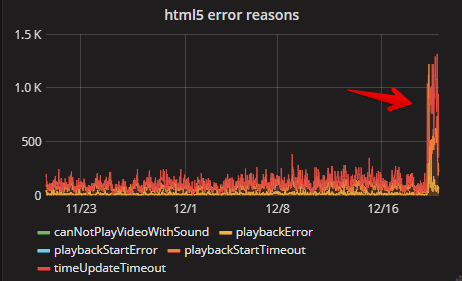
К тому моменту мы увидели, что где-то мы облажались. Закатав рукава, начался поиск проблем. Довольно оперативно были найдены десятки разнообразных недочётов: возникавшие таймауты из-за забитого thread pool в nodejs, ошибки логики, ошибки админов с конфигурированием, с системами оркестрации и т.д.
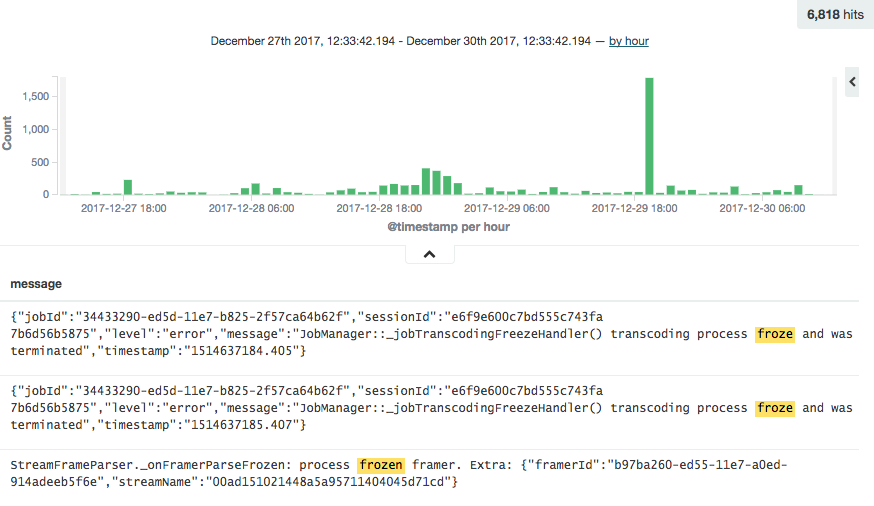
Всё это удавалось решить за считанные часы, но была одна проблема, что никак не поддавалась обьяснению, логи не содержали ничего аномального, проверки инфраструктуры и конфигов серверов с маршрутизаторами оказались безрезультатными. На транскодерах, что принимают входящие rtmp потоки от ingest серверов (а ingest от стримеров), занимаются перекодированием звука и видео в нескольких качествах, происходили фризы!
На обновленном транскодере был реализован механизм детекта фриза: транскодер-сервис завершал работу транскодер-процесса при отсутсвии видео/аудио фреймов на протяжении некоторого времени. Транскодер-сервис ещё уведомлял командный центр об этой проблеме, а командный центр пытался перезапустить часть таких задач. Транскодеры тянут rtmp потоки с ingest серверов, а в роли ingest серверов выступают серверы с wowza. Помимо транскодеров, с ingest тянут потоки: сервис контроля качества, сервис по нарезке preview с видеопотока, сервис записи… Почти на всех из них присутствует механизм определения фризов. Вот и всплыли эти множественные фризы на видеопотоках…
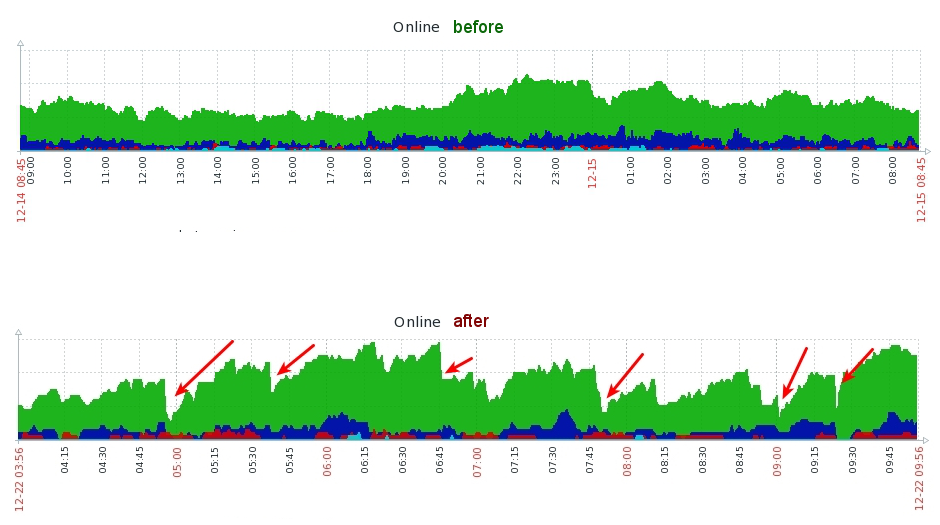
Помимо логов есть еще метрики! Ключевые метрики системы отправляются в zabbix, а быстрые или же не самые ключевые - в graphite. Перечитав логи и пересмотрев метрики, пришли к выводу, что фризы не единичные и возникают группами. График ниже отображает количество потоков после транскодирования, доступных к просмотру. До релиза и после релиза.
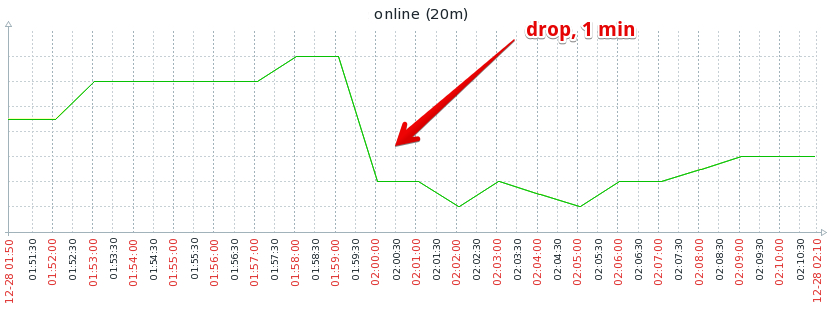
На большем масштабе это выглядело так
Пока творилась неразбериха, по одному из серверов был снят лог подключений и отключений стримеров, а также данные из лога по детекту фриза. Временной диапазон для анализа был взят из zabbix. Еще раз отмечу, что это один и тот же ingest сервер.
0ec147369caddd33ebdf95be72532cd1:
2017-12-28 01:29:42 published vss-w-p-6
2017-12-28 01:59:06 freeze on transcoder vss-crabscoder-9
2017-12-28 02:00:06 unpublished vss-w-p-6
52934993316c56a20731d755917e6146:
2017-12-28 01:30:55 published vss-w-p-6
2017-12-28 01:59:08 freeze on transcoder vss-crabscoder-6
2017-12-28 02:06:57 unpublished vss-w-p-6
27581ab5a170e0467261ad6fc070ee33:
2017-12-28 01:46:18 published vss-w-p-6
2017-12-28 01:58:55 freeze on transcoder vss-crabscoder-3
2017-12-28 02:05:53 unpublished vss-w-p-6
Но при этом были и потоки, что не фризились
49ee6016e84e6ae8d2000efac50ea7d6:
2017-12-28 00:46:19 published vss-w-p-6
2017-12-28 04:18:19 unpublished vss-w-p-6
3b125f18c52d9eb914144088ed8c142f:
2017-12-28 01:10:34 published vss-w-p-6
2017-12-28 06:39:44 unpublished vss-w-p-5
4cc7d1fb938038b774264e23450846b2:
2017-12-27 23:50:46 published vss-w-p-6
2017-12-28 02:45:24 unpublished vss-w-p-6
Факт 1. Не все потоки на одном и том же сервере испытывали проблемы
Вместе с тем, в логах Wowza ещё проскакивали записи о таймаутах
WARN server comment 2017-12-20 15:07:11 - - - - - 188991.31 - - - - - - - - LiveMediaStreamReceiver.doWatchdog: streamTimeout[origin/_definst_/d7350b04480f90affd092816157a8dba]: Resetting connection: wowz://10.2.1.174:1935/origin/_definst_/d7350b04480f90affd092816157a8dba
WARN server comment 2017-12-20 15:07:11 - - - - - 188991.311 - - - - - - - - LiveMediaStreamReceiver.doWatchdog: streamTimeout[origin/_definst_/7c4728f4a266216c1a9c2a9ebad191ed]: Resetting connection: wowz://10.2.1.174:1935/origin/_definst_/7c4728f4a266216c1a9c2a9ebad191ed
WARN server comment 2017-12-20 15:07:11 - - - - - 188991.312 - - - - - - - - LiveMediaStreamReceiver.doWatchdog: streamTimeout[origin/_definst_/a8643913cef9e21a403416018bdf8e88]: Resetting connection: wowz://10.2.1.174:1935/origin/_definst_/a8643913cef9e21a403416018bdf8e88
Факт 2. На Wowza наблюдается обрыв потоков по таймауту. Непонятно на приёме потока или раздаче.
В саппорт начали поступать жалобы от клиентов. Все ссылались, что их выкидывает из инфраструктуры. У каждого своё представление о том, что такое “выкидывает”, но саппорт выдвинул факт…
Факт 3. Стримеров периодически выкидывает принудительно из инфраструктуры.
Другая часть команды проверила логи на ingest, origin и транскодере, и пришла к выводу…
Факт 4. Поток обрывается на ingest, затем инфраструктура это замечает и шлёт команду остановить обработку на origin, дальше это замечает транскодер и мы наблюдаем SIGPIPE.
Отмечу, что SIGPIPE - это сигнал, что отправляется процессу в том случае, если соединение с сокетом, в который происходит запись процессом обрывается. Т.е. если писали в сокет, а он закрылся/сеть оборвалась.
Еще посмотрели график событий дисконектов с ingest, то стало понятно, что они были и раньше, но их было меньше. Штатные ли это дисконекты или нет по логам понять было нельзя.
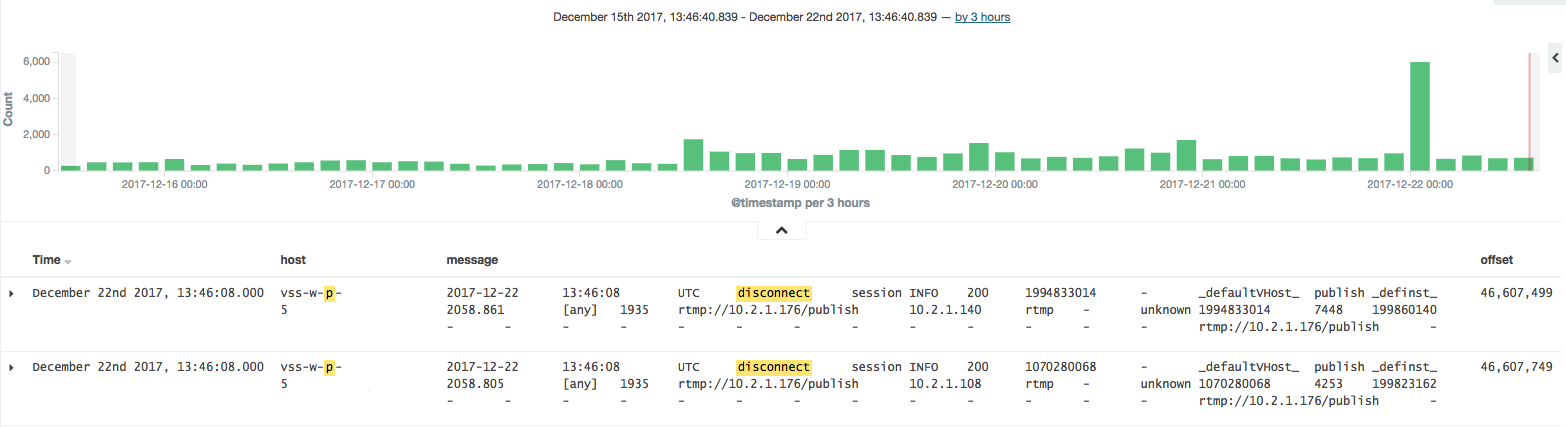
Факт 5. Количество дисконектов выросло на том же количестве трафика.
Последний факт всплыл из наблюдения за жизнью потоков. Выяснилось, что за сессии стриминга несколько раз мог наступить фриз или остановка процесса транскдирования по SIGPIPE сигналу, процесс транскодирования перезапускался и трансляция продолжалась.
Сведя все известные на тот момент факты, было выдвинуто предположение, что проблема с ingest слоем. На это указывали и фризы, которые были индикатором того, что не поступают данные потока, и обрывались не сразу все потоки, а только часть.
Ещё раз обсудили план действий и зафиксировали дальнейшие шаги:
- Проверить запросы со стороны бизнес логики, чтобы исключить, что вследствие бага мы сами всё убиваем
- Выяснить по логам, что или кто инициировал дисконнекты с инжеста. Пункт проблематичен, ибо потоки поступают от зоопарка софта, flash приложений, hardware encoders, OBS, X-Split и т.п. Каждое из приложений может вести себя иначе.
- Надо собрать полную карту действий стримеров от подключения до отключения, кто подключался на просмотр, кто отключался, как менялся статус потока. Всё, всё, всё.
- Проверить лог каждого из Wowza-сервисов по отдельности, на предмет наличия временных интервалов без логов (заблокировалось ПО, например).
- Кто оставался из стримеров после обрывов и есть ли какая-то корреляция?
- Проверить с дебаггерами вовзу и пересмотреть полный дифф между прошлой версией и текущей, при необходимости пересобрать Wowza с покрытием логами всех новых участков, а также проверить блокировки между процессами.
- Проверить idle и показатели как харднод серверов, так и виртуальных машин. Раньше мониторинг не замечал ничего, но мало ли…
- Даже проверить фронтенд клиентов, мало ли…
- Провести наблюдение за ingest, поснимать трафик, поснимать логи.
Чеклист первых предположений:
- виноват датацентр и проблема у них, где-то потери на канале
- виноваты админы, маршрутизатор или сервера
- виновата Wowza
Инженеры не признают проблем в коде! Конечно же, виноваты админы, сеть, сервера и даже небо, и даже Аллах. Админов начали допрашивать, а пока шёл допрос, они успели уточнить у датацентра, нет ли проблем. Датацентр не подтвердил наличие проблем, наши мониторинг тулы тоже не находили аномалий. Не было ни единого разрыва. Разработчики сразу припомнили админам все былые косяки. Была как-то проблема с прошивкой сетевой карты, и ответы nginx из ramfs занимали непристойно много. В тот раз админы не признавали наличие проблем до последнего, тоже винили разработчиков. Классика: админы винят девелоперов, а девелоперы винят админов. QA при этом винят всех, кроме себя.
Итого, работы разделены между разработчиками и админами, и все приступили к своей работе.
Спустя некоторое время, в логах consul были замечены проблемы с TCP соединениями, что имели место быть в то же время,
что и обрывы.
Dec 28 15:08:34 vss-w-e-3 consul[22751]: memberlist: Failed TCP fallback ping: read tcp 10.2.0.229:39386->192.168.8.3:8301: i/o timeout
consul используется в качестве service discovery всех сервисов системы. Тем не менее мы восприняли это как знак.
Наша уверенность в инфраструктурной проблеме усиливалась.
При анализе логов были найдены слабые места, когда не хватало в логах информации. Заводятся задачи на расширение собираемых данных в логи, а это всё затягивает отладку. Так, например, новый транскодер не в полной мере уведомлял, кто генерировал задачи и отправлял управляющие команды. А это очень критично для восстановления всей картины…
Таких мелких косяков множество, и они тормозят выяснение.
Поимом прочего, я себе взял пункт 9. Доля такая у CTO… вечно заниматься неформализованным хардкором в условиях неопределенности. В рамках этого пункта решено было начать с исследования потоков с ingest, а именно видео части.
Неплохо было бы получить полный вывод по каждому
фрейму видео и аудио: размер, дату, найти некоторые корреляции. Для анализа видео, как статического, так и live,
есть замечательный инструмент ffprobe. ffprobe позволяет в риалтайме получать
информацию о потоке, информацию о фреймах, длительность фрейма, время по шкале encoder на стороне, отправляющей поток.
30 минут, и я написал скрипт на nodejs для контроля за ingest серверами и логирования вывода ffprobe по всем потокам
на всех серверах.
Для соблюдения достоверности добавлю и саму команду:
ffprobe -i rtmp://host:port/path -show_frames
Но вывод покажет последовательность фреймов, а ещё интересно смотреть за временем, когда эти фреймы были получены
процессом ffprobe. Так можно определить отставания и залипания. Для этих целей я прикрутил
запись в лог файл ffprobe с интервалом раз в 5 секунд временной метки.
Код написан и запущен, а я засел смотреть логи кибаны и график заббикса.
Через 40 минут были словлены фризы. Потирая руки, лезу анализировать вывод ffprobe.
[FRAME]
media_type=video
stream_index=0
key_frame=1
pkt_pts=117285
pkt_pts_time=117.285000
pkt_dts=117285
pkt_dts_time=117.285000
best_effort_timestamp=117285
best_effort_timestamp_time=117.285000
pkt_duration=33
pkt_duration_time=0.033000
pkt_pos=3406194
pkt_size=32358
width=854
height=480
pix_fmt=yuv420p
sample_aspect_ratio=1:1
pict_type=I
coded_picture_number=456
display_picture_number=0
interlaced_frame=0
top_field_first=0
repeat_pict=0
[/FRAME]
[FRAME]
media_type=video
stream_index=0
key_frame=1
pkt_pts=127421
pkt_pts_time=127.421000
pkt_dts=127421
pkt_dts_time=127.421000
best_effort_timestamp=127421
best_effort_timestamp_time=127.421000
pkt_duration=33
pkt_duration_time=0.033000
pkt_pos=3440357
pkt_size=35030
width=854
height=480
pix_fmt=yuv420p
sample_aspect_ratio=1:1
pict_type=I
coded_picture_number=457
display_picture_number=0
interlaced_frame=0
top_field_first=0
repeat_pict=0
[/FRAME]
На следующий день начал анализировать собранные логи. Для этого написал
простенький скрипт, который вытаскивал
pkt_dts_time из лога и агрегировал по 5-и секундным интвервалам количество фреймов. Еще он считал
количество фреймов в метках реального времени, которые я писал в файл. После построения
gnuplot скриптом графика стали видны дропы
визуально.
PTS - presentation time stamp, DTS - decoding time stamp. В фрейме pkt_pts_time и pkt_dts_time будут отличаться только при наличии predictive (P) кадров. Так что для анализа можно взять DTS и разница между pkt_dts_time у двух последовательных фреймов будет отображать время между энкодингом двух фреймов. Подробнсости тут.
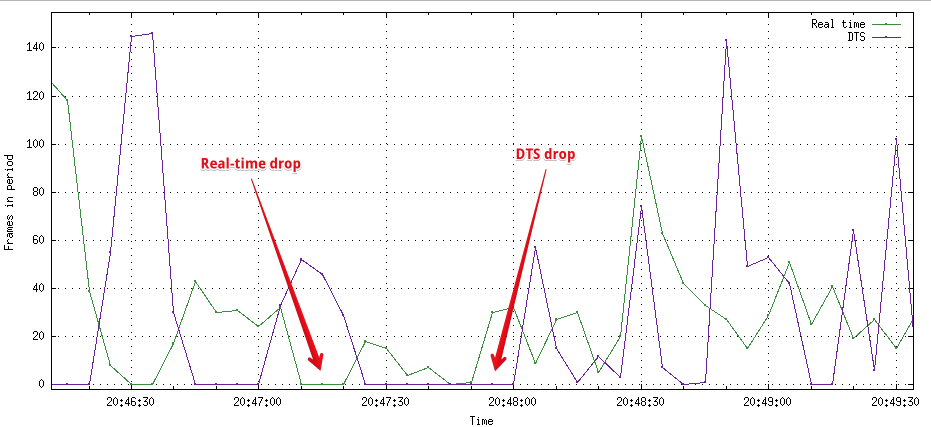
Судя по графику, со стримами происходило чёрт знает что, fps не выдерживался, вечно скакал, DTS (decoding time stamp) менялся паблишинг клиентом и перескакивал на несколько десятков секунд вперёд. По realtime графику видно, что и Wowza отдавала фреймы для ffprobe с фризами. Сам график количества фреймов в realtime не показал ничего нового, ведь и так ловили эти проблемы на транскодерах. График количества фреймов в DTS timebase был довольно интересным. Так вести себя энкодер на стороне стримера может в том случае, если Wowza не читает входящий поток из сокета. В этом случае клиент просто пропускает фреймы и ждёт, пока буфер на стороне Wowza очистится.
Подозрение пало на Wowza.
Пора рассказать о Wowza. Это проприетарный софт с закрытым кодом и помесячной оплатой, крутыми возможностями за свои деньги. Пока ты реально не начинаешь пользоваться продуктом… Идёт время, ты вляпываешься в проблемы и странное поведение, пишешь саппорту. Бравый саппорт отвечает через пару дней и запрашивает логи. Окей, высылаешь им логи. Ничего, что логи уже были приатачены к тикету, конфигурация была описана, может что пропустили. Ребята тупят ещё пару дней и запрашивают полные логи. Ну ладно, хотите читать несколько гигабайт логов с момента запуска? Пожалуйста. Проходит ещё пару дней, саппорт запрашивает еще логи. WTF? Какие ещё логи? Саппорт непреклонен: по вашим логам мы не можем понять проблему, дайте больше логов. Откуда ж их взять, если и так debug режим включён? Пацанов это не волнует! “Дайте больше логов!” - наверняка так выглядит их корпоративный лозунг. Один раз, на IBC в Амстердаме, мы познакомились с их топ руководством и хотели помитинговать на их стенде, и таки решить с ними проблемы. От нашей идеи их Vice President of Engineering приуныл, но предложил бухнуть с ними, а проблемы пообещал порешать после IBC. Стоит ли уточнить, что в итоге они снова выпали на мороз?
Тем не менее надо решать проблему. Чтобы исключить Wowza можно было бы поднять nginx с
nginx-rtmp-module, а перед Wowza ingest поставить haproxy/teeproxy/etc и
дублировать трафик. Можно было бы дублировать трафик правилами iptables. Тогда можно было бы дублировать один и тот же
поток на два разных приложения принимающих rtmp и смотреть разницу на них. Идея провалилась, так как у rtmp
присутствует handshake и второй nginx с nginx-rtmp-module просто отвергнет соединение из-за кривых ответов на handshake.
Пока думали над возможностью таки распараллелить потоки, убрали проверку фризов с транскодеров. Проблему это не решило. Транскодер продолжал ждать, но и на origin не отправлял фреймы. Origin ждал несколько десятков секунд, и затем сам закрывал соединения с транскодером. Эти закрытия тоже детектились транскодером, и он завершался с сигналом SIGPIPE.
Тем временем, начали обсуждать блокировки на стороне Wowza…
На нашей сборке Wowza присутствуют самописные модули для авторизации, контроля прав, уведомлений о покдлючениях, отключениях, allow lists и т.п. Wowza запускает множество тредов и слушает входящие rtmp соединения. На серверах достаточно оперативной памяти и ядер, а нагрузка менее 10%. Так что, перегрузы сразу исключили.
Но остались вопросы с модулями. В самописных модулях Wowza, на Java, в shared memory хранятся хэшмапы с информацией о стримах, о серверах для нотификаций. Получение IP адресов, на которые требуется слать уведомление, происходит по интервалу (раз в 5 секунд), и результат пишется в shared memory. Для того, чтобы безопасно читать и писать из shared memory, требуется ставить блокировки. В Java коде это решается либо явно, либо с использованием synchronized блоков. У нас использовался второй вариант, но сути это не меняет.
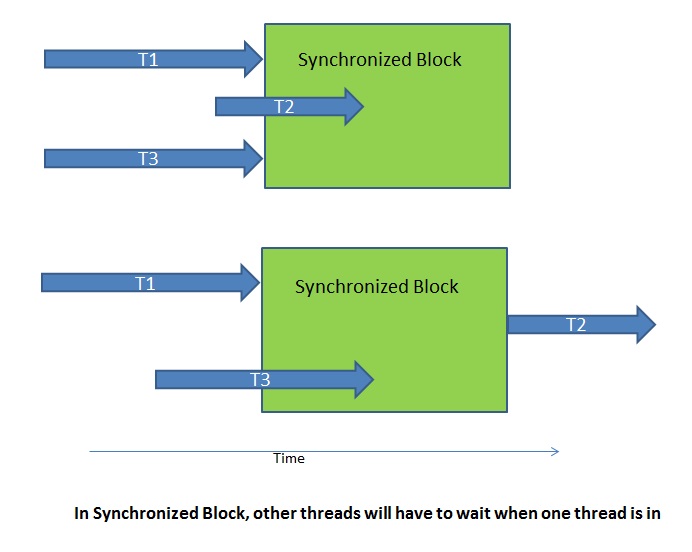
Потому возникло предположение, что Wowza где-то блокируется, то ли из-за нашего кривого кода, то ли из-за её кода. Проверить это можно только покдлючившись к процессу strace’ом. strace
- это довольно мощный инструмент для низкоуровневой отладки: он пишет системные вызовы, пишет аргументы, переданные функциям, возвращённые значения после выполнения функций, время выполнения функции, а также pid сабпроцесса/треда, в котором происходил вызов.
Админы сразу выполнили strace -c -f -p123. Аргумент -c указывает считать количество времени, вызовов и ошибок
в каждом из системных вызовов. Вывод на работающем ingest был таковым:
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
98.27 164058.185756 129258 1269232 328380 futex
0.96 1607.779169 10882 147742 epoll_wait
0.26 437.918455 283 1546081 198 write
0.20 339.308117 86119 3940 poll
0.15 245.116958 247 991033 clock_gettime
0.09 148.213531 3293634 45 41 restart_syscall
0.05 89.647620 280 319628 144406 read
0.00 4.673533 268 17416 lseek
0.00 1.546572 239 6478 getrusage
0.00 1.316333 243 5408 346 epoll_ctl
Выше уже шла речь, что система не особо была нагружена, потому сразу же предположили, что странное творилось с Wowza, и множество потоков ожидали снятия блокировок. TL команды сразу начал заниматься кодом модулей Wowza в таком порядке:
- статический анализ diff кода до релиза и после
- добавить логирование входов/выходов в synchronized блоки в нагих модулях, проведённое время и количество претендентов заблокировать блок.
Такой анализ позволил бы найти место, где ставилась блокировка, код подвисал, и остальные треды ждали снятия блокировки. Если учитывать, что в коде была работа с другими сервисами по сети, то долгий ответ или тормоза в обработке ответов запросто могли блокировать остальные треды.
Следующая гипотеза - блокируются наши самописные модули Wowza.
Пока TL занимался Wowza модулями, я продолжил долбаться с strace, и решил собрать вообще лог всех вызовов и пытаться
восстановить историю, хоть и с bird eye view.
Чтобы собрать всё, что мне было нужно, потребовалось запустить strace -t -T -f -p123, где
123- pid Wowza процесса;-tдобавляет в начало строки дату и время, нам крайне важно для сопоставления проблем;-Tдобавляет время, затраченное на вызов, об этом отдельно ниже расскажу;-fдобавляет pid child процесса в вывод, для мультипоточных приложений без этого флага никуда
За 22 минтуы с одного ingest собрали 5Гб логов, промежуток с 2017-12-28 13:58 по 2017-12-28 14:20.
Выглядят они примерно следующим образом:
26484 13:58:09 futex(0x7f4d7006ff38, FUTEX_WAKE_PRIVATE, 1 <unfinished ...>
26477 13:58:09 futex(0x7f4d70064904, FUTEX_WAIT_PRIVATE, 1432479, NULL <unfinished ...>
25693 13:58:09 futex(0x7f4d60445e18, FUTEX_WAKE_PRIVATE, 1 <unfinished ...>
25225 13:58:09 <... futex resumed> ) = -1 EAGAIN (Resource temporarily unavailable) <0.000164>
24755 13:58:09 <... futex resumed> ) = 0 <0.000165>
30942 13:58:09 read(125, <unfinished ...>
20197 13:58:09 write(178, "\307", 1 <unfinished ...>
13033 13:58:09 epoll_ctl(132, EPOLL_CTL_MOD, 159, {EPOLLIN, {u32=159, u64=159}} <unfinished ...>
9900 13:58:09 write(145, "\307", 1 <unfinished ...>
14275 13:58:09 write(176, "\307", 1 <unfinished ...>
21229 13:58:09 <... write resumed> ) = 104 <0.000134>
26484 13:58:09 <... futex resumed> ) = 0 <0.000134>
25693 13:58:09 <... futex resumed> ) = 0 <0.000125>
25225 13:58:09 futex(0x7f4db0006e28, FUTEX_WAKE_PRIVATE, 1 <unfinished ...>
30942 13:58:09 <... read resumed> "\304\262-\244\324\327H\200\266\27#\27)\213\274\r\341\247,Z\373\227\334#-\242l\321\254b@\220"..., 65000) = 105 <0.000109>
20197 13:58:09 <... write resumed> ) = 1 <0.000115>
13033 13:58:09 <... epoll_ctl resumed> ) = 0 <0.000118>
21229 13:58:09 write(149, "G\0\0\37\0\4^\t", 8 <unfinished ...>
26484 13:58:09 futex(0x7f4d7007c834, FUTEX_WAKE_OP_PRIVATE, 1, 1, 0x7f4d7007c830, {FUTEX_OP_SET, 0, FUTEX_OP_CMP_GT, 1} <unfinished ...>
25225 13:58:09 <... futex resumed> ) = 0 <0.000095>
30942 13:58:09 read(125, <unfinished ...>
20197 13:58:09 write(178, "\343g\265c\177\232\365~\376\307w\337e\314(\227\33\251\357\363\327\372Z\374}\6\210~\344\34\246\263"..., 512 <unfinished ...>
13033 13:58:09 epoll_wait(132, <unfinished ...>
9900 13:58:09 <... write resumed> ) = 1 <0.000277>
Разберём этот кусок построчно.
25693 13:58:09 futex(0x7f4d60445e18, FUTEX_WAKE_PRIVATE, 1 <unfinished ...>
pid child процесса 25693, вероятно это один из тредов Wowza. В 13:58:09 был осуществлён системный вызов
futex.
Futex - это механизм (и он же системный вызов) для возможности реализации синхронизации между потоками в user-space,
а с использованием shared memory ещё и между разными процессами, правда в этом случае придётся таки выполнить операцию
в kernel-space. Возможность синхронизации в user-space работает на порядок или даже два быстрее, чем при использовании
логики в kernel-space. Дело в том, что при синхронизации в user-space не требуется останавливать выполнение приложения
и не требуется переключаться на выполнение кода ядра, что экономит много ресурса CPU. Системный
вызов futex атомарно проверяет ячейку памяти на соответствие определённому значению и блокирует выполнение потока в котором был
запущен (вызов). Это важная часть работы с многопоточными приложениями, использующими доступ к разделяемым ресурсам из
разных потоков. Без блокировок несколько потоков могут попытаться получить доступ к одному и тому же ресурсу и всё
может выполняться не так, как задумал программист. Знаете шутку?
“I had a problem, so I decided to use threads. tNwoowp rIo bhlaevmes”? Эволюция механизмов блокировок и их минусы/плюсы
интересная тема, заинтересованным можно начать с перечня публикаций
в этом ответе на Quora.
В данной публикации есть примеры кода для понимания логики
работы futex. Нам же достаточно фактов, что futex без таймаута может неограничено долго блокировать другие потоки,
вызывая деградацию, а еще в случае краха треда, что ставил блокировку, могут не снятся локи в остальных потоках (от
реализации зависит, а она black box у нас).
Интерфейс системного вызова таков:
int futex(int *uaddr, int op, int val, const struct timespec *timeout, int *uaddr2, int val3);
Первый аргемунт uaddr (значение uaddr === 0x7f4d60445e18) может
пригодиться, если несколько потоков с разными pid попытаются поставить блокировку с тем же адресом. В этом случае
по uaddr можно найти тред, который успешно поставил блокировку, и выяснить, почему он долго её не снимал. uaddr
является указателем на область памяти.
Вызов futex был осуществлён с аргументом FUTEX_WAIT_PRIVATE, и это указывает системному вызову, что требуется
сравнить значение по адресу uaddr с третьим аргументом, в нашем случае это 1, и заблокироваться
(возможно с таймаутом, но вызов был без таймаута).
Первая строчка файла - это pid child процесса. Как видно из лога, результат этого вызова находится несколькими
строчками ниже, с тем же pid:
25693 13:58:09 <... futex resumed> ) = 0 <0.000125>
Результат выполнения 0, и это означает, что блокировка снята (для операции FUTEX_WAIT_PRIVATE).
Операции чтения и записи (read
и write) работают с файловыми дескрипторами, и без
контекста сложно понять, с чем связан дескриптор. Но до чтения или записи должен либо открыться файл, либо сокет,
так что, стоит искать другие системные вызовы по этому файловому дескриптору и идентифицировать, что же это
за файл. Хорошо, что read возвращает количество прочитанных байт, что полезно для анализа, а по логу вызова write
можно увидеть желаемое количество байт для отправки и фактическое значение. Для гадания на кофейной гуще подойдёт!
Итого, есть множество строк чтения и записи, известны их дескрипторы. Задача состоит в том, что требуется найти сокет нашего залипшего соединения, как и тред, в котором выполнялось чтение и запись.
На помощь мне пришла смекалка. Протокол
rtmp реализовывает RPC можно начать искать по командам.
Нас интересует паблишинг стрима на Wowza, а, согласно rtmp, для начала паблишинга требуется вызов
команды createStream.
The client sends this command to the server to create a logical channel for message communication The publishing of audio, video, and metadata is carried out over stream channel created using the createStream command. The command structure from the client to the server is as follows:
+--------------+----------+----------------------------------------+
| Field Name | Type | Description |
+--------------+----------+----------------------------------------+
| Command Name | String | Name of the command. Set to |
| | | "createStream". |
+--------------+----------+----------------------------------------+
| Transaction | Number | Transaction ID of the command. |
| ID | | |
+--------------+----------+----------------------------------------+
| Command | Object | If there exists any command info this |
| Object | | is set, else this is set to null type. |
+--------------+----------+----------------------------------------+
Клиент plain text’ом будет слать createStream, и он будет находиться в начале пакета. Если мне
повезёт, то createStream будет находиться в первых десятках байт, и эта строка попадет в strace.
В противном случае пришлось бы искать по другим заголовкам, и было бы сложнее.
$ grep -n "createStream" strace_wowza_p5_13-58_14-20
7557250:20197 14:00:47 <... read resumed> "C\0\1\33\0\0\32\21\0\2\0\fcreateStream\0@\0\0\0\0\0\0"..., 65000) = 34 <0.000159>
17282898:20197 14:04:16 <... read resumed> "C\0\3\36\0\0\32\21\0\2\0\fcreateStream\0@\0\0\0\0\0\0"..., 65000) = 34 <0.000099>
22014818:21229 14:06:01 <... read resumed> "C\0\2]\0\0\32\21\0\2\0\fcreateStream\0@\0\0\0\0\0\0"..., 65000) = 34 <0.000114>
30542512:20197 14:09:07 <... read resumed> "C\0\3\36\0\0\32\21\0\2\0\fcreateStream\0@\0\0\0\0\0\0"..., 65000) = 34 <0.000100>
31817555:14275 14:09:36 <... read resumed> "\3\0\0\334\0\0\32\21\0\0\0\0\0\2\0\fcreateStream\0@\0\0"..., 65000) = 38 <0.000143>
32871539:9900 14:09:59 <... read resumed> "\3\0\2J\0\0\32\21\0\0\0\0\0\2\0\fcreateStream\0@\0\0"..., 65000) = 38 <0.000078>
46524834:21229 14:14:57 <... read resumed> "\3\0\2%\0\0\32\21\0\0\0\0\0\2\0\fcreateStream\0@\0\0"..., 65000) = 38 <0.000141>
46607865:30942 14:14:59 <... read resumed> "C\0\2f\0\0\32\21\0\2\0\fcreateStream\0@\0\0\0\0\0\0"..., 65000) = 34 <0.000132>
48653251:21229 14:15:42 <... read resumed> "\3\0\1\r\0\0\32\21\0\0\0\0\0\2\0\fcreateStream\0@\0\0"..., 65000) = 38 <0.000186>
Бинго! Есть подключения. Интересно, что в треде с pid === 20197 аж 3 стрима нашлось.
Теперь на помощь придут логи кибаны. По ним стоит поискать начало операции стриминга и
сопоставить, были ли в период наблюдения за Wowza фризы.
Стримы нашлись:
a144380f9dd83643c756884ca1d55150:
2017-12-28 14:04:17 published vss-w-p-5
2017-12-28 14:17:28 SIGPIPE from origin
2017-12-28 14:23:20 unpublished vss-w-p-5
5773e9ab70202cbb98868e477aff0d1a:
2017-12-28 14:06:01 published vss-w-p-5
2017-12-28 14:07:48 freeze on transcoder vss-crabscoder-8
2017-12-28 14:09:56 unpublished vss-w-p-5
e8024496a02282138285b6f2460e5bdc:
2017-12-28 14:11:25 published vss-w-p-5
2017-12-28 14:17:40 SIGPIPE from origin
2017-12-28 14:41:19 unpublished vss-w-p-5
4852e7d0125ab780057742a78edae88d:
2017-12-28 14:14:58 published vss-w-p-5
2017-12-28 14:17:21 SIGPIPE from origin
2017-12-28 14:24:52 unpublished vss-w-p-5
4a8a32f1ea637df5c1900e5c0c2fb407:
2017-12-28 14:15:00 published vss-w-p-5
2017-12-28 14:17:21 SIGPIPE from origin
2017-12-28 14:23:34 unpublished vss-w-p-5
Поработаем с тредом с pid === 20197, в котором происходило чтение сразу двух проблемных стримов. Отсекаем лишние данные и грепаем только по этому pid.
$ grep '^20197' strace_wowza_p5_13-58_14-20 > strace_p5_20197
Результирующий файл получился немаленьким. 368 Мб. Теперь поищем дескриптор.
$ grep 'createStream' -C 2 strace_p5_20197
--
20197 14:04:16 <... epoll_wait resumed> \{\{EPOLLIN, {u32=99, u64=13110842216018870371}\}\}, 8192, 500) = 1 <0.011427>
20197 14:04:16 read(99, <unfinished ...>
20197 14:04:16 <... read resumed> "C\0\3\36\0\0\32\21\0\2\0\fcreateStream\0@\0\0\0\0\0\0"..., 65000) = 34 <0.000099>
20197 14:04:16 read(99, <unfinished ...>
20197 14:04:16 <... read resumed> 0x7f4dc01b4170, 64966) = -1 EAGAIN (Resource temporarily unavailable) <0.001609>
--
Искомый дескриптор 99.
Посмотрим, сколько было чтений по этому дескрпитору. Подготовим данные для gnuplot в виде времени (посекундная агрегация) и количества вызовов read за эту секунду.
$ grep 'read(99,' strace_p5_20197 | cut -f2 -d' ' | uniq -c | awk '{$1=$1};1' > data.txt
Построил график, и получилось следующее…
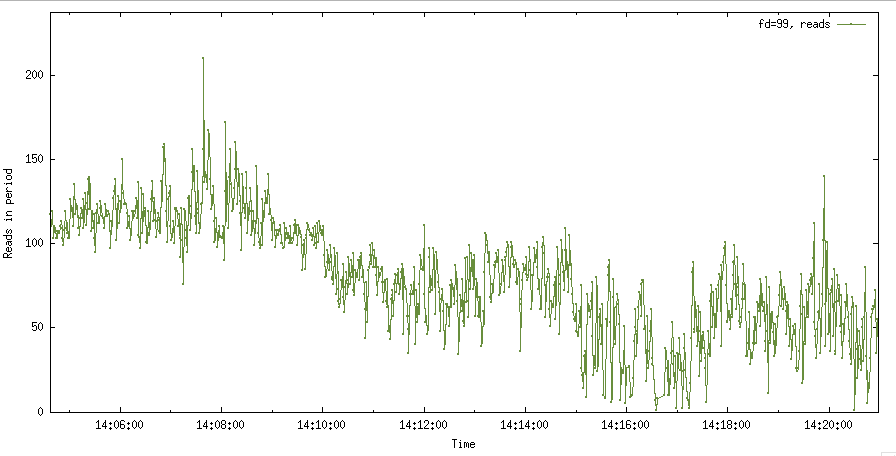
Странно, количество чтений упало, но они не пропали полностью. Приблизив график, в 14:16:35 - 14:16:45 видны проблемы.
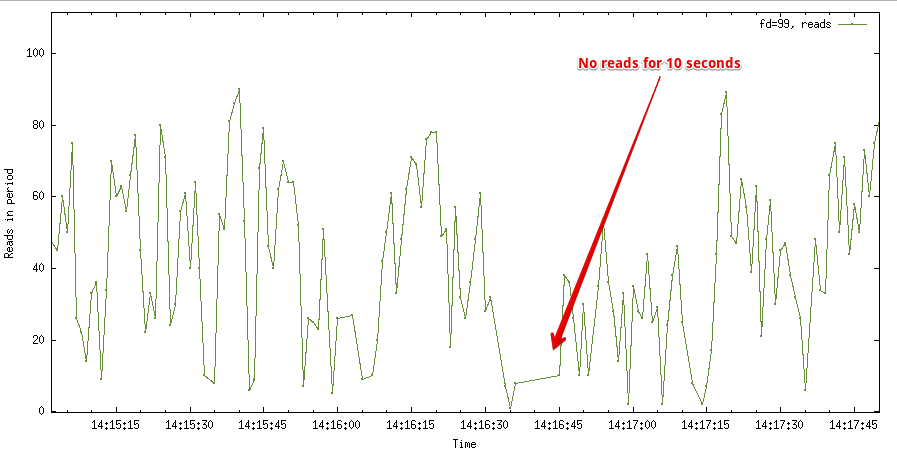
По прямой линии между точками делаю вывод, что чтений не было в этом интервале. Если не было чтений, то и не было записей потребителям, например, тому же транскодеру. Тем не менее решил проверить распределение read и write по всему треду.
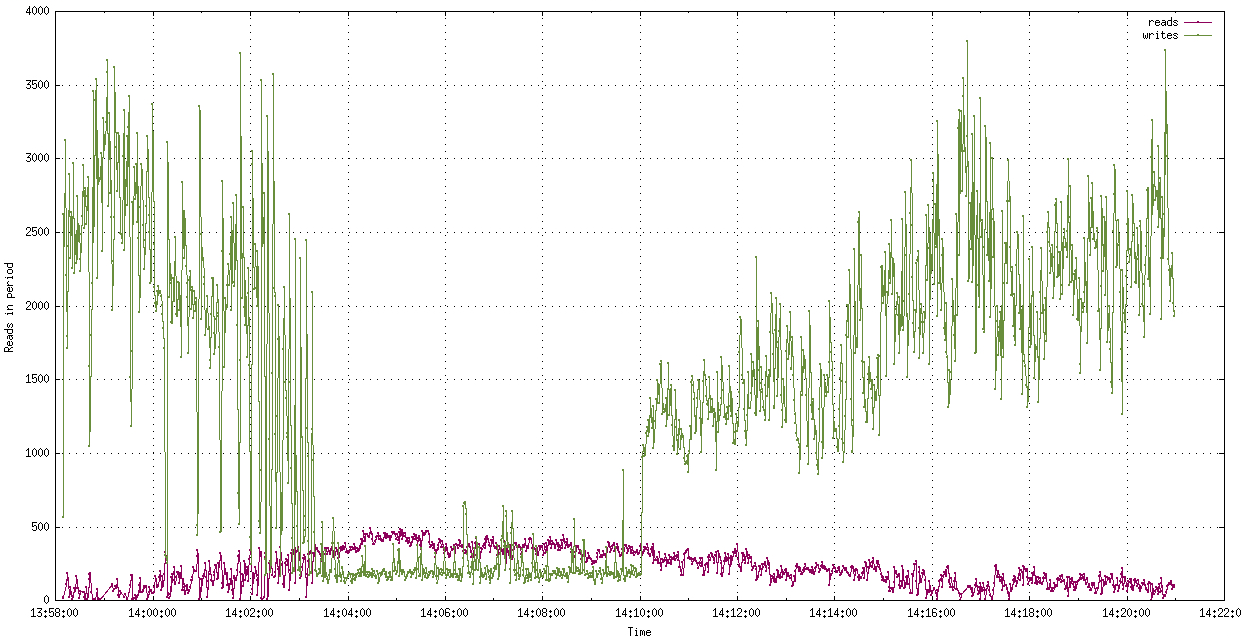
График странный. Количество чтений могло упасть из-за отключения стримеров. Тред перестал бы их процессить, и при следующем подключении чтение сокетов могло попасть в другой тред. Но странным показалось то, что при падении операций чтения на порядок, операции записи даже подросли и разброс вызовов снизился: чем больше чтений, тем больше колебаний по оси Y на графике между соседними временными интервалами).
Далее grep, sed и awk меня не хватило, да чего там таить, всей душой нанавижу sed и awk с их отвратительным синтаксисом. Настало время пописать ещё немного на js. Я накидал код, который парсит весь лог strace для треда и для каждого файлового дескриптора считает количество чтений, записей, количество записанных и прочитанных байтов. Код на github, там же пример скрипта для gnuplot для построения.
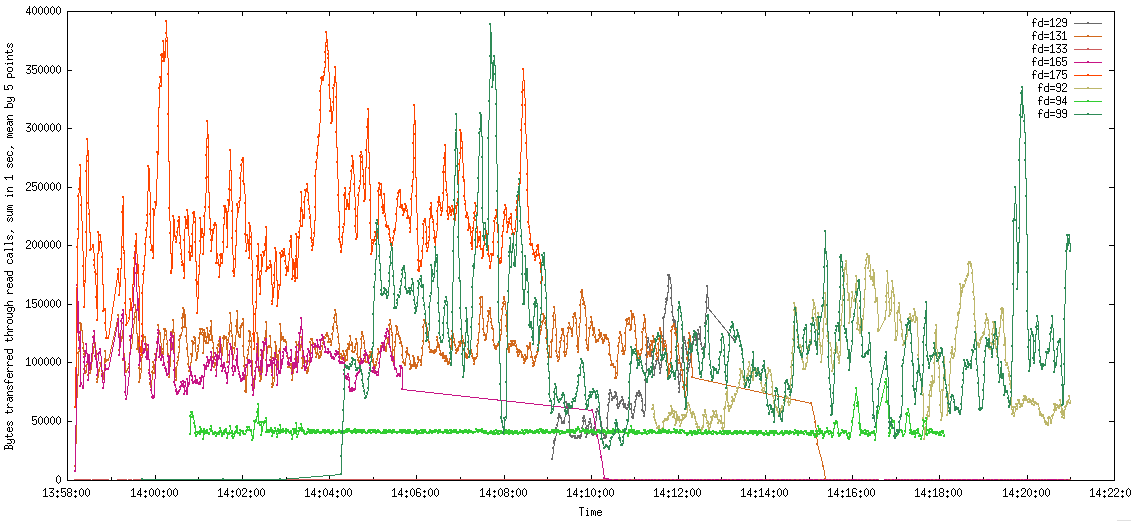
На первом графике - суммарное время выполнения read/write вызова для конкретного файлового дескриптора, просуммированное за интервал в 1 секунду. На втором графике отображена сумма прочитанных байтов за интервал в 1 секунду для каждого файлового дескриптора. Дескрипторы, не связанные с rtmp потоками, я исключил. Туда попали всякие пинги наличия потока и т.д. Они не влияют существенно на общую картину.
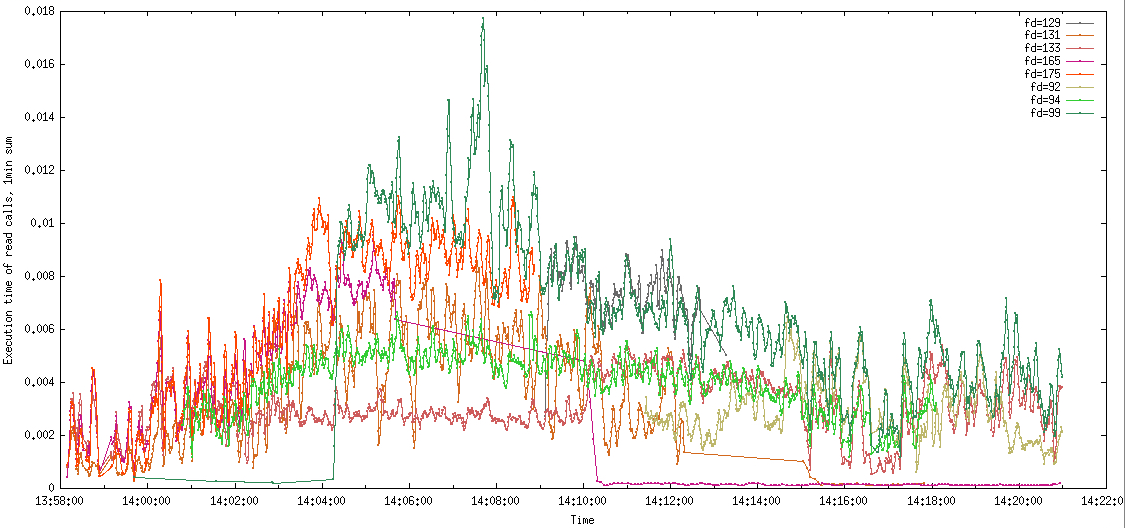
Всплески exec time для read на fd=99 до 18мс коррелируют с интенсивным чтением. Прочитал этот fd в ту секунду 380Кб. 18мс на 380Кб. Не фонтан, конечно, но и не очень плачевно. По крайней мере, явно не в чтениях дело.
А что с записями?
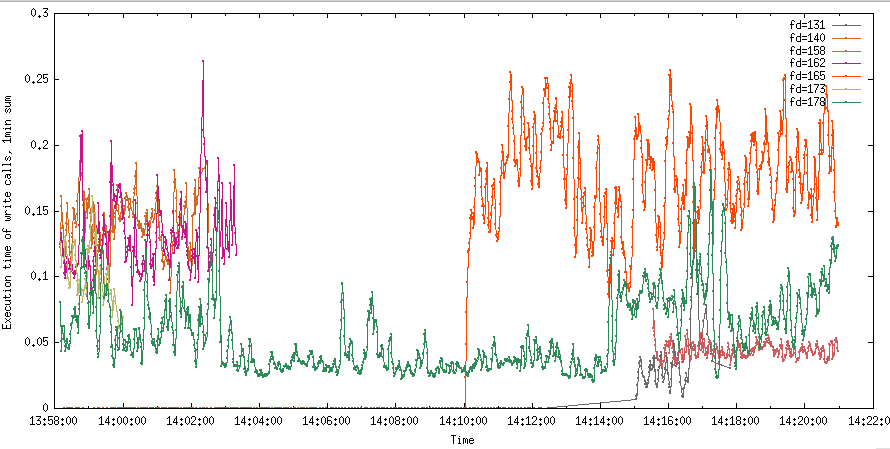
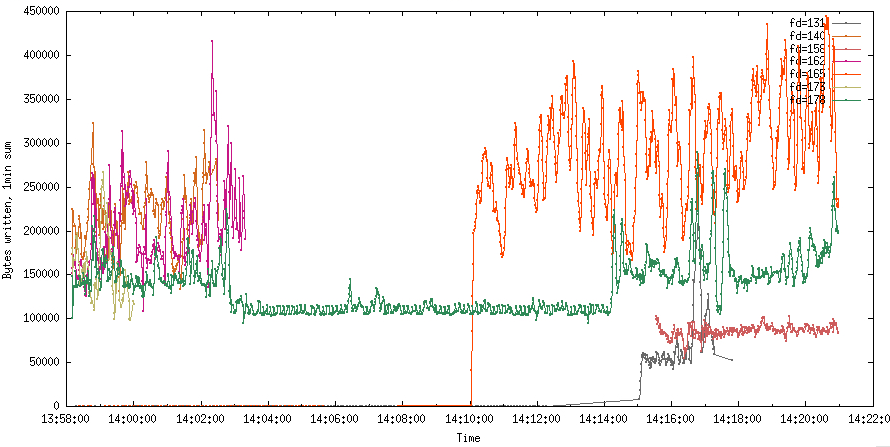
Воу-воу! Это что, для fd=165 требовалось больше 200мс каждую секунду с 14:10:00 для того, чтобы отправлять по 300Кб? Остальные не лучше. По графику хорошо видно, что подключение новых слушателей (те, кому write вызовы шлют контент) вызывает деградацию у остальных вызовов write? А отключение, как было после 14:02:00, уменьшает тайминг?
Тогда можно предположить, что из-за медленного write не успевают в рамках треда отправляться данные во все сокеты. А Wowza ещё и читает контент…
К этому моменту TL дописал код Wowza модулей и поставил логирование всего, что только возможно, в местах, где есть synchronized блоки и прочие блокировки. Блокировки в модулях не были обнаружены.
Два независимых подтверждения, что не в блокировках дело. Нужно разбираться, что происходит с ОС.
Следующая гипотеза - кривая настройка ОС.
Сразу скажу, что у нас железо всё своё. Никакие клауды не дадут такого контроля и стоимости, потому только bare metal, только хардкор.
Начинаем перебирать всё, что может влиять на работоспособность системы:
-
Тюнинг TCP стека, хорошие матераилы по этой теме раз, два. Замеры в одной из статей свидетельствуют, что тюнинг может дать улучшение результатов замеров в 4-5 раз.
-
Interrupts (hardware interrupts and software interrupts). Возможно NIC TX/RX буфер переполняется и происходит повторная доставка.
-
Наблюдение за переполнениями буферов NIC,
ethtoolи т.д. -
Huge pages - по умолчанию CentOS аллоцирует память блоками по 4K. Если включить Huge Pages, то эффективность повысится. Были выключены вовсе.
С тюнингом TCP сделали всё, что можно, подняли буфера до рекомендуемых значений, провели теоретический рассчёт даже. Да и всю ОС пересмотрели по критичным настрйокам. Рекомендую статью от RedHat про тюнинг к прочтению и настройки для раздачи видео от знакомого проекта.
Нашли ненастроенные куски, например, лимит на открытые файлы, установленный в дефолтные 1024. Результата значительного это не дало, потом перешли к тюнингу CPU affinity, буферам NIC и т.п.
Отдельно поверхностно пройдёмся по interrupts, буферам NIC (network interface controller) и процессу доставки данных от NIC до приложения.
Сетевая карта (NIC) обладает микропроцессором и может либо использовать интегрированную память для буферов, либо использовать RAM системы. Большинство интегрированных карт дешевле сотен долларов используют RAM и аллоцируют память прямо в RAM, наши карты входят в число таких, потому в тексте далее исходим из того, что речь идёт о NIC без собственной памяти. При регистрации драйвера NIC выделяется память под буферы на отправку (TX ring buffer) и получение данных (RX ring buffer).
Количество буферов задаётся настройками, может тюниться, а современные карты поддерживают сотни и тысячи таких буферов. Важно понимать, что буфера кольцевые. Если один буфер имеет размер в 200 байт и данные из буфера не прочитаны и не обработаны, то следующая порция данных перетрёт “самые старые” данные в буфере. Таким образом, если не вычитываются данные из буффера NIC, то они будут вытеснены и, как следствие, неприятное поведение гарантировано.
У большинства компонентов компьютеров есть сигнальные протоколы, и NIC тому не исключение. Когда NIC фиксирует получение данных и записывает в RX buffer эти данные, то NIC должен уведомить ядро о поступлении новых данных. Для этого и используются IRQ (Interrupt ReQuest). NIC шлёт IRQ, CPU обрабатывает этот IRQ и вызывает код, который вычитает данные из RX buffer и передаст дальше на обработку. Дальше пакеты пройдут уже не через код драйверов, а через network подсистемы ядра, правильно разобьются по протоколам, будет определено приложение-получатель, и уже в буфера сокетов будут доставлены данные. Приложению останется прочесть данные из этого сокета.
Вернёмся на шаг назад. Как NIC запишет данные в буфер в RAM? Ещё лет 10 назад NIC требовалось иметь свою собственную память и по запросу ядра отдавать данные, находящиеся в ней. Сейчас везде используется DMA (Direct Memory Access) - технология, что позволяет делать прямые обращения к выделенной области RAM непосредственно со сторонних устройств, минуя CPU, системные вызовы и т.д. Доступ к этим участкам памяти есть и у CPU и, как следствие, у ядра, потому время между получением данных NIC, записью в RAM и получением этих данных ядром уменьшилось, что положительно сказалось на производительности. Резюмирую, NIC пишут данные в RAM посредством DMA, а затем NIC генерирует IRQ сигнал, чтобы ядро могло обработать эти данные.
IRQ, о которых шла речь выше, являются hardware interrupts и вынуждают CPU останавливать выполнение кода и переключаться на обработку прерывания. Когда в системе много трафика, то NIC будет тысячи раз в секунду генерировать IRQ и вынуждать process switching, тяжелую операцию. Потому появилось улучшение и был придуман механизм SoftIRQ, и включён в ядра ОС, а для драйверов NIC был разработан NAPI механизм.
Драйвера, которые поддерживают NAPI, теперь могут предоставить poll функцию, которую будет использовать ядро для опроса
буферов. Ядро же регистрирует эти poll функции и запускает их в отдельных тредах. Они видны в top как ksoftirqd.
Когда прилетает самый первый пакет устройству с NAPI и SoftIRQ поддержкой, то NIC пошлёт IRQ. IRQ вызовет обработчик,
что включит механизм polling. Как только он включён, то треды ksoftirqd будут с определённой частотой опрашивать
буфера и при необходимости запускать обработку пакетов, находящихся в них. При этом, пока происходит polling, то
отключается обработка IRQ. Такой подход позволяет существенно экономить ресурсы и не допускать переключений контекста.
Если пакетов станет критически мало, то CPU будет зря пытаться проверять наличие данных и зря тратить процессорное
время. Чтобы и тут сэономить, происходит отключение polling и включение штатных IRQ. Когда поток пакетов станет высок, то
произойдёт снова включение polling.
Отдельный тюнинг может быть произведён с CPU affinity, позволяющим
привязать процессы ksoftirqd к определённому CPU/ядрам, что увеличит локальность кэша CPU и пропускную
способность.
Если тема с IRQ, SoftIRQ и поведением ядер в real-time системах заинтересовала, то рекомендую просто отменный цикл публикаций для детализации, что происходит под капотом ядра и драйверов NIC, а ещё обзорные презентации номер 1 и номер 2.
Фух, теоретическая часть закончена, опустимся на землю.
Тулзой ethtool можно посмотреть настройки NIC, посмотреть версию драйвера и понаблюдать за статистикой.
# ethtool -i eth1
driver: tg3
version: 3.137
firmware-version: FFV7.8.16 bc 5720-v1.32
# ethtool -g eth1
Ring parameters for eth1:
Pre-set maximums:
RX: 2047
RX Mini: 0
RX Jumbo: 0
TX: 511
Current hardware settings:
RX: 200
RX Mini: 0
RX Jumbo: 0
TX: 511
В выводе выше видно, что драйвер tg3, а карточка в сервере Broadcom 5720 1Gb. Смутил размер RX буфера, что равен
200 байт. Как-то чертовски мало, потюнили и это. TX буфера тоже малы. Самое печальное, что для TX максимальное значение
равно 511 и оно не меняется без
пересборки драйвера из исходников.
Масла в огонь подливала статистика, хотелось бы видеть 0…
25673 packets pruned from receive queue because of socket buffer overrun
173905 packets collapsed in receive queue due to low socket buffer
Для оценки производительности сети и TCP стека существует много инструментов. Самый известный, пожалуй, iperf.
Он позволяет замерять пропускную способность между двумя хостами в сети, имеет множество настроек. Вывод примерно таков
>iperf3 -c hostname -u -b9G -w2m -i2
[ ID] Interval Transfer Bandwidth Total Datagrams
[ 4] 0.00-2.00 sec 2.07 GBytes 8.91 Gbits/sec 248878
[ 4] 2.00-4.00 sec 2.08 GBytes 8.91 Gbits/sec 249020
[ 4] 4.00-6.00 sec 2.11 GBytes 9.07 Gbits/sec 253434
[ 4] 6.00-8.00 sec 2.11 GBytes 9.08 Gbits/sec 253730
[ 4] 8.00-10.00 sec 2.03 GBytes 8.73 Gbits/sec 244013
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bandwidth Jitter Lost/Total Datagrams
[ 4] 0.00-10.00 sec 10.4 GBytes 8.94 Gbits/sec 0.008 ms 0/1248863 (0%)
[ 4] Sent 1248863 datagrams
Мы погоняли и его, он показал вроде плюс-минус приемлемые данные, но был ряд недостатков:
- многопоточность;
- отсутствие тонких настроек параметров соединений.
Достоверным назвать такой замер было нельзя.
К этому моменту я разобрал влияние самого strace на замеры. Я понимал, что он может вносить деградацию на время
замеров и их искажать. Тому были найдены подтверждения и сферические
цифры в вакууме.
К тому же, данных не хватало и хотелось залезть на уровень профайлинга ядра Linux. Наступила эра perf.
С perf сразу же столкнулись с потоком проблем.
1) Отсутствием поддержки в ядрах OpenVZ 2.6.32, которые мы использовали в продакшне для виртуализации debufs.
Окей, ищем опцию, включающую debufs, она была найдена в vzkernel-debug ядре.
2) Места в / не хватило на железках, чтобы поставить vzkernel-debug.
Окей, расширяем место, админы шаманят.
3) Место есть, ядро поставлено, но даже с perf_event_paranoid нельзя запустить в контейнере.
Окей, ставим руками Wowza на хардноду и пытаемся запустить.
4) Не заводится, не видит доступных для наблюдения функций.
Окей, пересобираем ядро и путём проб и ошибок находим весь пул настроек, что ему нужны. Вот он:
CONFIG_FRAME_POINTER = and
CONFIG_BOOT_PRINTK_DELAY = and
CONFIG_FAULT_INJECTION = and
CONFIG_FAILSLAB = y
Мои нервы закончились на шаге 2, и пока админы сражались с проблемами, я поднял на AWS EC2 два dedicated сервера в одном и том же az для своих экспериментов, ведь опыта с perf у нас не было.
Главный источник знаний в сети по perf является Brandan Gregg, и в своём блоге у него ценнейшая база знаний. Вооружившись статьей Netflix о профайлинге с помощью perf приложений на java, начал разбираться с Wowza на EC2.
Пока наши работы синхронизировались, я уже успел поиграться с perf на EC2 и получил практический опыт работы с ним, и начали делать замеры на нашем железе.
Стоит ли говорить, что инструменты вокруг perf и дальше подолжали падать? Я уже смирился, что череда сложностей и неудач преследует нас. Надо было освятить сервера, что ли.
# /root/perf-map-agent/bin/perf-java-top 11139
perf: Segmentation fault
-------- backtrace --------
perf[0x4ee551]
/lib64/libc.so.6(+0x32510)[0x7f339968c510]
perf[0x433e7a]
perf(cmd_top+0x101e)[0x434fde]
perf[0x467503]
perf(main+0x649)[0x468279]
/lib64/libc.so.6(__libc_start_main+0xfd)[0x7f3399678d1d]
perf[0x41b839]
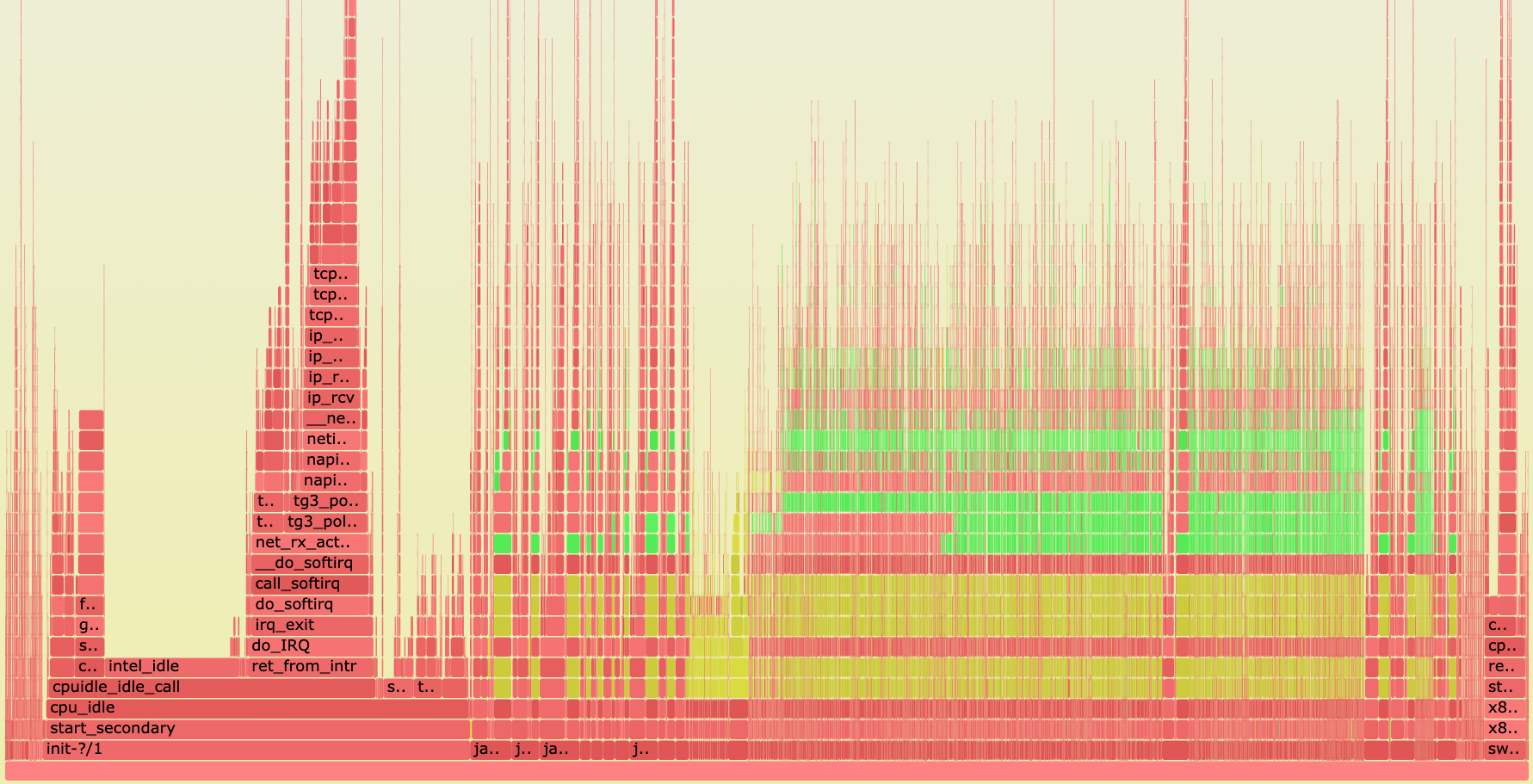
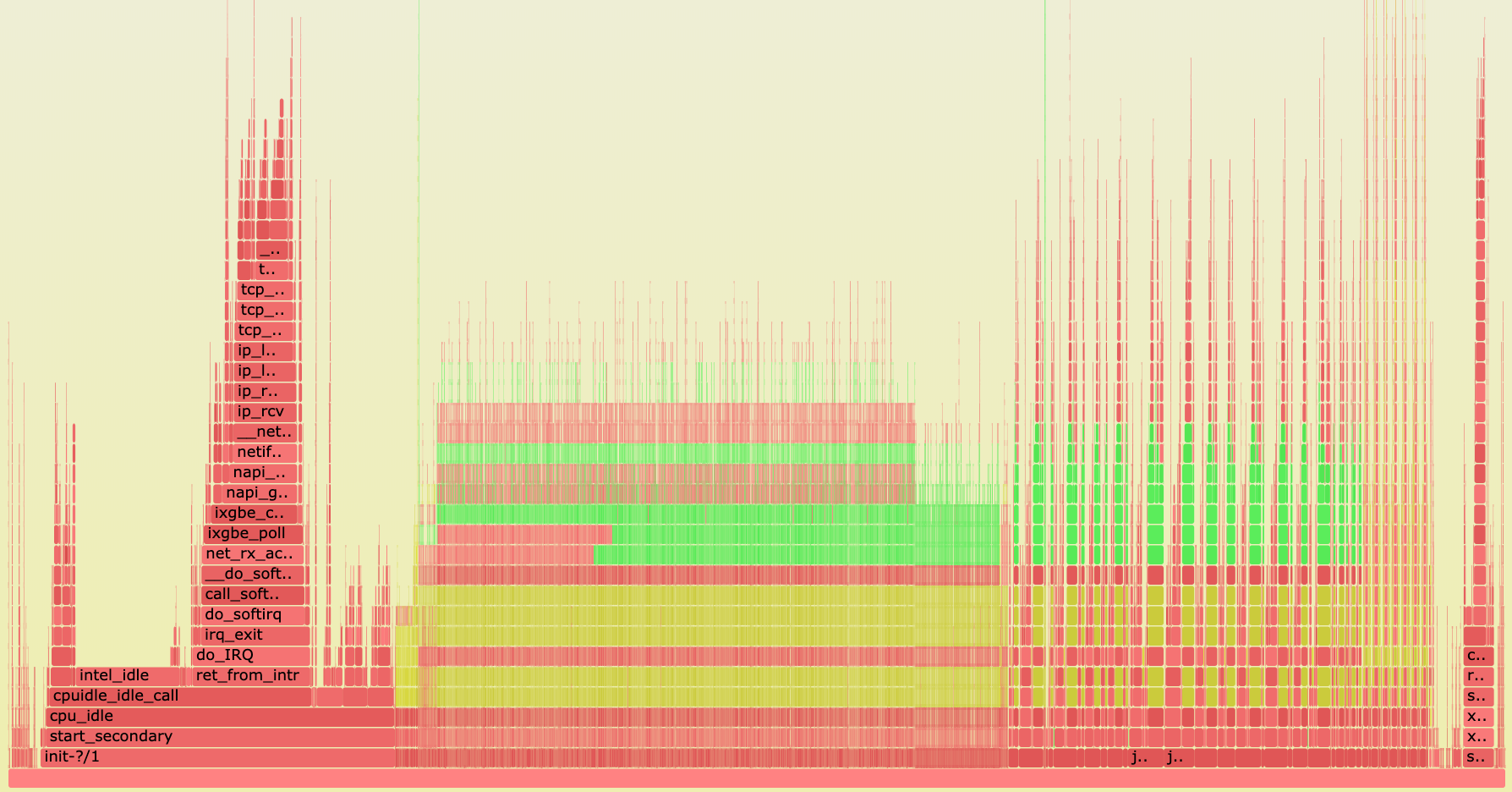
Когда свершилось чудо, и perf собрал статистику по одному из проблемных ingest серверов, мы увидели следующее.
Картина по всем процессам.
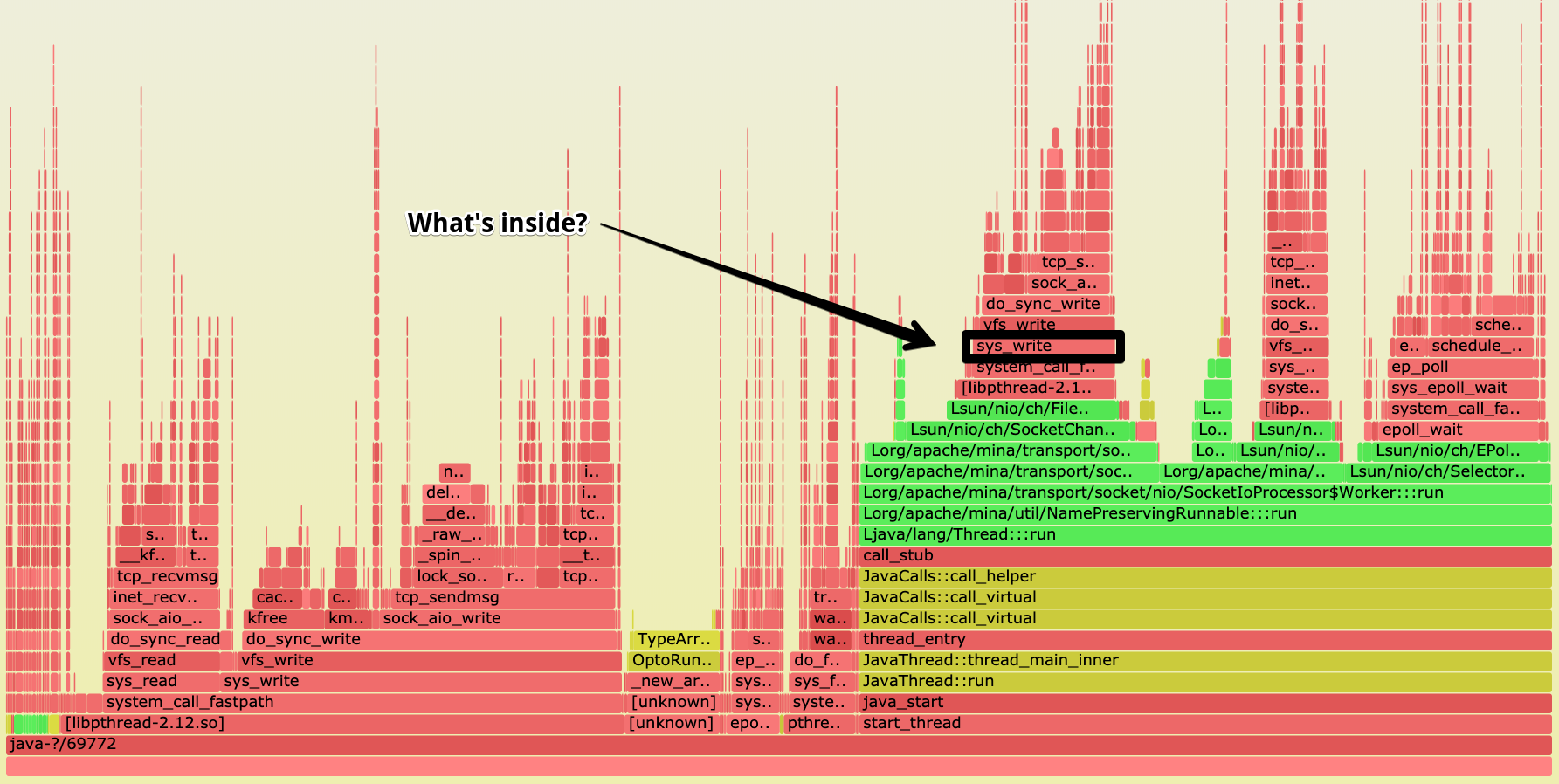
Картина по самому потребляющему ресурсы java процессу.
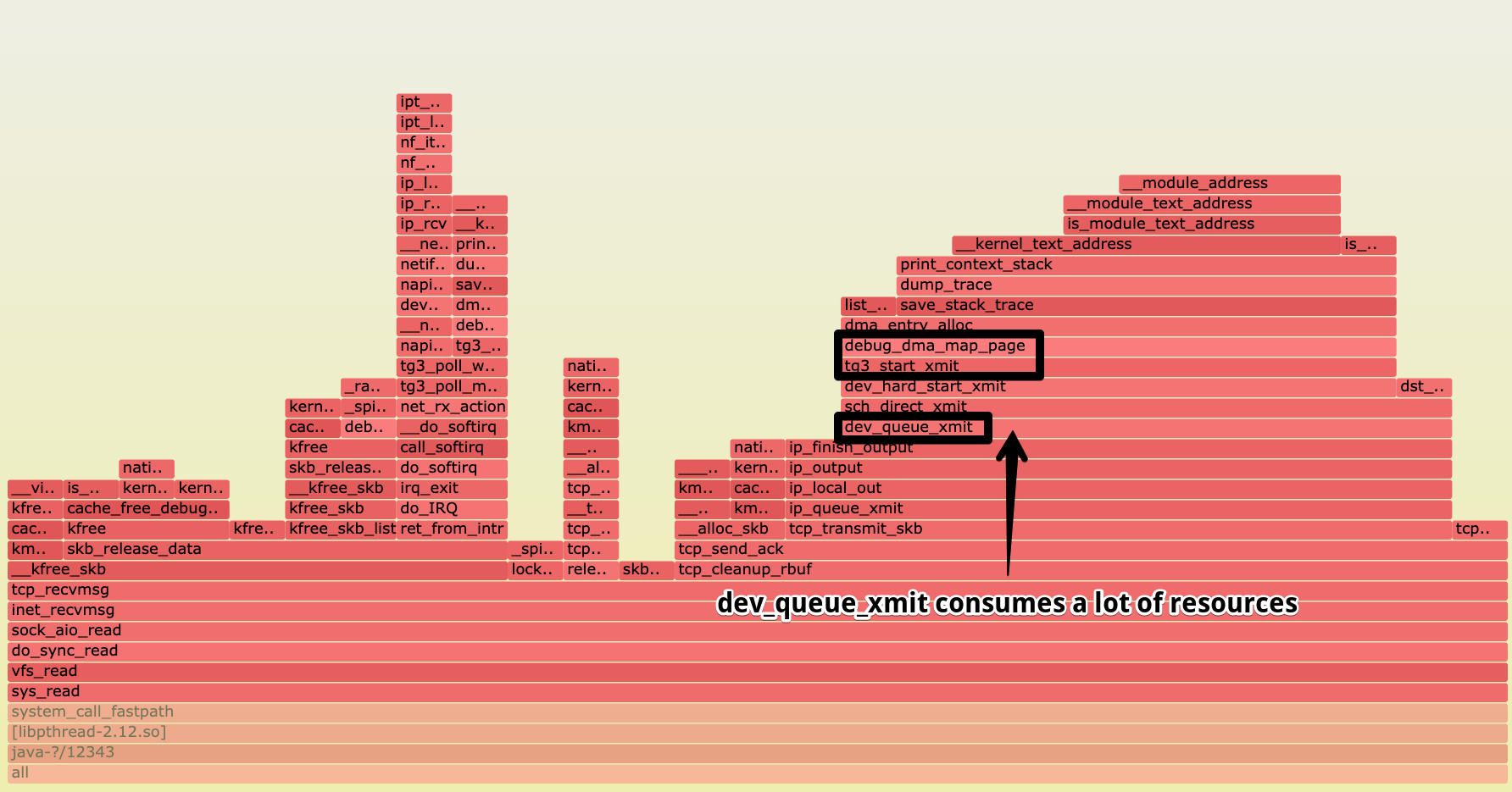
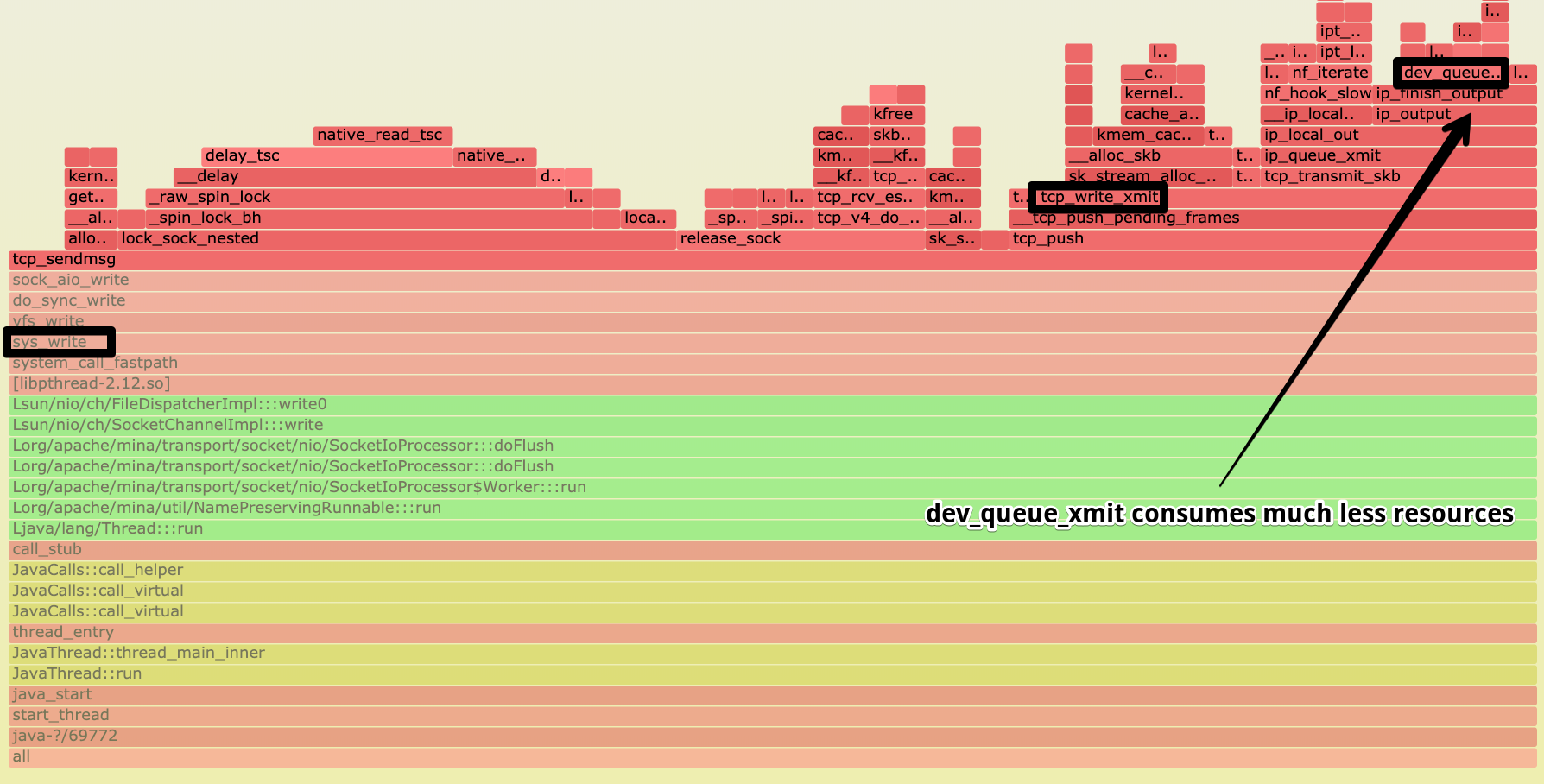
На графике видны вызовы функций драйвера NIC (tg3). Например, функция отправки tg3_start_xmit. Внимание привлёк на
себя вызов debug_dma_map_page, сделанный из tg3_start_xmit. Судя по потреблению, больше всего отъела эта ветка
выполнения. Внутри ещё видны save_stack_trace, print_context_stack и так далее. Мы не то чтобы знали код драйверов,
которые используем, но ничего не оставалось, как закатать рукава и окунуть руки в драйвера tg3.
А как дела на AWS EC2 серверах? Чтобы иметь эталон для сравнения, были подняты сервера с хорошей сетевой
производительностью, поднята Wowza, а трафик отправлен на этот сервер. Под нагрузкой сняты показатели perf.
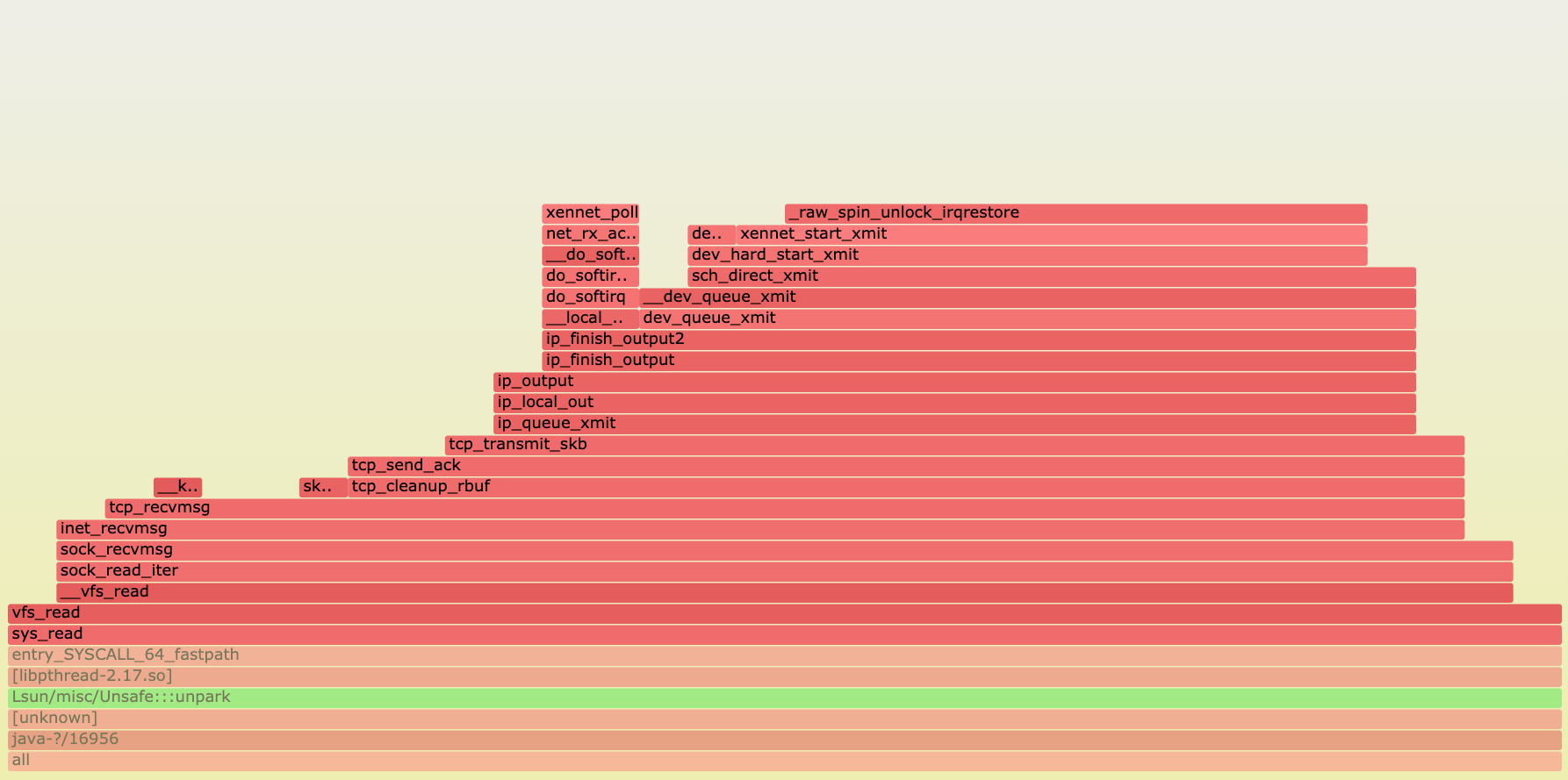
Как видно, никаких проблем не наблюдается. Дополнительных тяжёлых вызовов внутри xennet_start_xmit нет (xennet - это
paravirtualized network interface для гипервизора Xen, виртуальные машины в EC2 на базе Xen работают). Кстати, на
EC2 танцев с бубном не потребовалось, perf завёлся сразу.
Надо копать под драйвер. Код драйвера находится в ядре; подобрав версию vzkernel, что была у нас, приступил к анализу.
В драйверах возле кода tg3_start_xmit были найдены комментарии
/* The EPB bridge inside 5714, 5715, and 5780 and any
* device behind the EPB cannot support DMA addresses > 40-bit.
* On 64-bit systems with IOMMU, use 40-bit dma_mask.
* On 64-bit systems without IOMMU, use 64-bit dma_mask and
* do DMA address check in tg3_start_xmit().
*/
...
/* Need to make the tx_cons update visible to tg3_start_xmit()
* before checking for netif_queue_stopped(). Without the
* memory barrier, there is a small possibility that tg3_start_xmit()
* will miss it and cause the queue to be stopped forever.
*/
Дальнейший разбор дал следующее:
- tg3 драйвер при проблемах с DMA (direct memory access) не пишет сообщений никуда, не инкрементит счётчики ошибок. Молча игнорирует;
- в данных
perfмного времени уходило наdebug_dma_map_pageи работу с некими ошибками DMA; - при ошибках DMA пакеты могут приходить битыми, теряться;
- поддержка DMA debug появилась в ядре Linux 3.9;
- даже у голого Centos 7 (а мы жили на Centos 6 based ядре) не весь debug функционал портирован;
- но в Centos 7 есть драйвера, что не игнорируют ошибки DMA;
- читать исходники ядра для неподготовленного человека психологически сложно.
Обладая этим набором данных решено было подобрать NIC, исходя из наличия трекинга ошибок DMA. Sic!
Такими драйверами были ixgb и ixgbe, Intel карточки на 10G. С включённым дебагом они будут писать инфо в
/sys/kernel/debug/ixgb или /sys/kernel/debug/ixgbe, при невозможности замапить регион под TX buffer будет осуществлена
запись в dmesg: “TX DMA map failed”. ethtool -c же будет выводить статистику rx_page_failed и tx_page_failed.
Хоть что-то.
По стечению обстоятельств, карточка Intel X540-T2 была на складе у датацентра, и драйвера подходили. Оставалось её оперативно установить, накатить новое ядро Linux и продолжить эксперименты. Первое хорошее событие? Пфф, сейчас. Датацентр профакапил и установил карту Intel I350-T2. Пришлось её менять. Потом DRAC (baseboard management controller от Dell) не завёлся, и пришлось разбираться, что не так насетапали. В моей истории хорошие события не происходят!
Когда подняли ядро с правильной карты, результаты получились следующие.
Настройки пободрее у X540:
[[email protected] ~]# ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 2048
RX Mini: 0
RX Jumbo: 0
TX: 512
На первый взгляд срез по всем процессам выглядит так же. Если копнуть под самый тяжелый java процесс, то увидим
Внешне отличия заметны. Я уже откупорил шампанское, проблема решена. Через несколько часов снова начали наблюдаться фризы.
Решено было провести замеры производительности сети, пока новая карта установлена.
Для наших экспериментов использовался sockperf. Компания, что его разрабатывает,
известный игрок на рынке low latency NIC и свои инструменты они приспособили для расширенного анализа.
Главный плюс, что sockperf можно задать параметры для теста в точности как у Wowza: TCP_NODELAY, epoll_wait таймаут,
писать данные по N байт.
TCP_NODELAY выключает алгоритм Нейгла. Если этот алгоритм включён, то возможно увеличение latency.
А подолбаться с установкой того же sockperf тоже пришлось. В Epel бажная версия, необходимо было пересобирать руками. Это
всё время, которого нет.
Стоит отметить, что для максимальной достоверности тесты проводились между проблемными ingest и транскодером, чтобы всё было честно, маршруты были те же, и не оказалось, что настройки сети кривые, и на других машинах проблему не увидим.
[[email protected] ~]# echo "T:10.2.1.152:11110" > s.list
[[email protected] ~]# sockperf ping-pong -f s.list -F e -t 10 --timeout 1 -m 512 --tcp-avoid-nodelay --nonblocked --tcp-skip-blocking-send --mps 10000
sockperf: == version # ==
sockperf[CLIENT] send on:sockperf: using epoll() to block on socket(s)
[ 0] IP = 10.2.1.152 PORT = 11110 # TCP
sockperf: Warmup stage (sending a few dummy messages)...
sockperf: Starting test...
sockperf: Test end (interrupted by timer)
sockperf: Test ended
sockperf: [Total Run] RunTime=10.450 sec; SentMessages=59403; ReceivedMessages=59402
sockperf: ========= Printing statistics for Server No: 0
sockperf: [Valid Duration] RunTime=10.000 sec; SentMessages=56984; ReceivedMessages=56984
sockperf: ====> avg-lat= 87.675 (std-dev=20.998)
sockperf: # dropped messages = 0; # duplicated messages = 0; # out-of-order messages = 0
sockperf: Summary: Latency is 87.675 usec
sockperf: Total 56984 observations; each percentile contains 569.84 observations
sockperf: ---> observation = 2431.621
sockperf: ---> percentile 99.999 = 1964.399
sockperf: ---> percentile 99.990 = 903.950
sockperf: ---> percentile 99.900 = 171.824
sockperf: ---> percentile 99.000 = 117.329
sockperf: ---> percentile 90.000 = 100.605
sockperf: ---> percentile 75.000 = 91.773
sockperf: ---> percentile 50.000 = 85.400
sockperf: ---> percentile 25.000 = 79.114
sockperf: ---> observation = 74.393
[[email protected] ~]# sockperf ping-pong -f s.list -F e -t 10 --timeout 1 -m 14 --tcp-avoid-nodelay --nonblocked --tcp-skip-blocking-send --mps 10000
sockperf: == version # ==
sockperf[CLIENT] send on:sockperf: using epoll() to block on socket(s)
[ 0] IP = 10.2.1.152 PORT = 11110 # TCP
sockperf: Warmup stage (sending a few dummy messages)...
sockperf: Starting test...
sockperf: Test end (interrupted by timer)
sockperf: Test ended
sockperf: [Total Run] RunTime=10.450 sec; SentMessages=69431; ReceivedMessages=69430
sockperf: ========= Printing statistics for Server No: 0
sockperf: [Valid Duration] RunTime=10.000 sec; SentMessages=66536; ReceivedMessages=66536
sockperf: ====> avg-lat= 75.076 (std-dev=20.043)
sockperf: # dropped messages = 0; # duplicated messages = 0; # out-of-order messages = 0
sockperf: Summary: Latency is 75.076 usec
sockperf: Total 66536 observations; each percentile contains 665.36 observations
sockperf: ---> observation = 1521.846
sockperf: ---> percentile 99.999 = 1450.021
sockperf: ---> percentile 99.990 = 914.075
sockperf: ---> percentile 99.900 = 223.133
sockperf: ---> percentile 99.000 = 100.173
sockperf: ---> percentile 90.000 = 84.808
sockperf: ---> percentile 75.000 = 80.184
sockperf: ---> percentile 50.000 = 70.178
sockperf: ---> percentile 25.000 = 68.719
sockperf: ---> observation = 66.878
Первый тест отправлял пакеты по 512 байт, а второй по 14 байт. Настройки были взяты с поведения реального приложения, то,
что замеряли еще strace. Результат средней задержки 87.675 usec и 75.076 usec соответственно.
Порывшись в интернете, обнаружил результаты замеров на EC2 инстансы, которые плюс-минус соотвествуют результатам полученным на Intel X540-T2 и Centos 7.
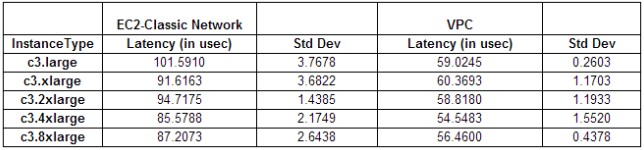
Фризы есть, но проблема не в сети. Проблема с Centos 6 и Broadcom 5720 явно была, её устранили, но это не помогло глобально.
Следующая гипотеза? Нет гипотезы! Мы все умрём!
Эксперименты выше занимали не один день, ведь ввод и вывод серверов для экспериментов требует вывода их на обслуживание, ожидание часами, пока не уйдёт нагрузка, ввод, ожидание… Целая спецоперация!
Пока экспериментаторы выдвигали и опровергали гипотезы, была доработана наша супер модуль на nodejs
video-quality-tools, доступная на Github.
Задача
video-quality-toolsзаключалась в real-time мониторинге за видеопотоком, анализе технических харакетристик: fps, bitrate. Модуль позволяет контролировать частоту создания кадров на стороне стримера (иначе говоря, на encoder), замерять фактические значения после получения по сети. Такой механикой можно понимать, где деградация сети, а где деградация на стороне пользователя, например, CPU перегружен у пользователя.
Модуль был успешно использован, была поднята Grafana с InfluxDB и начался сбор метрик с ingest серверов в разрезе каждого потока на ingest. Это куда удобнее, чем использовать gnuplot, к тому же полный real-time и возможность моментально реагировать.
Grafana начала показывать fps (frames per seconds), как они получались модулем (не на энкодере).
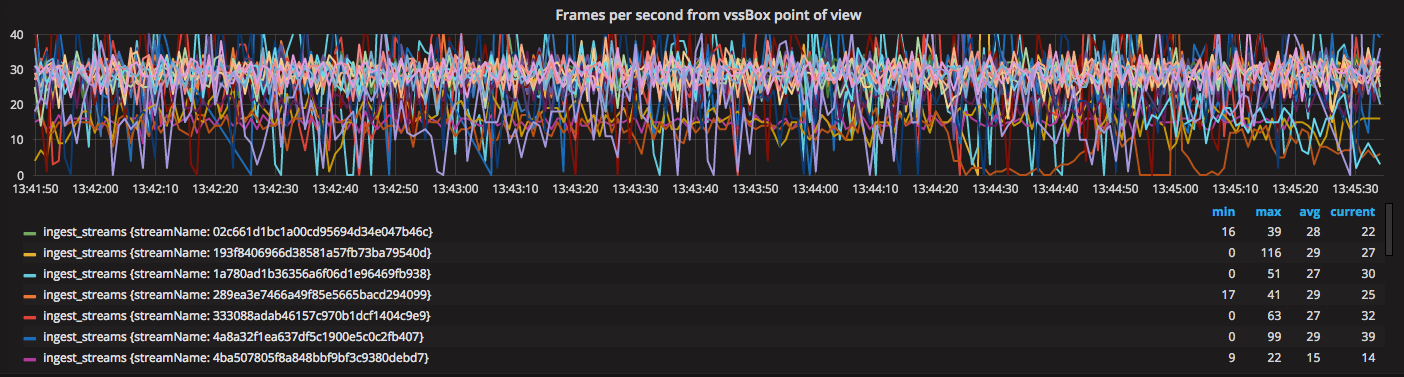
Имея один ingest на Centos 7 с новой картой, появилась возможность сравнить один и тот же поток, кодируемый одним и тем же оборудованием, из той же локации, но на двух разных версиях ядра и сетевых карт.
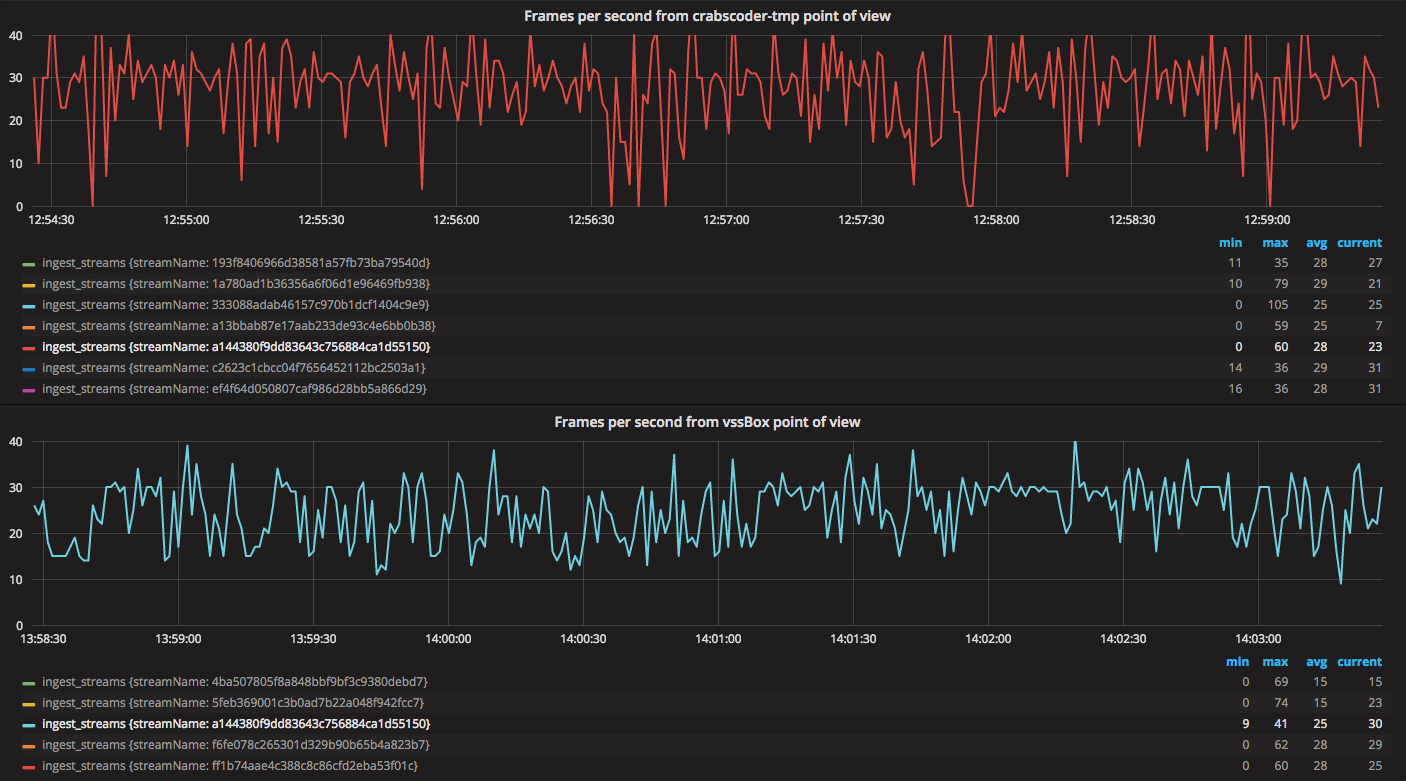
Centos 7 вёл себя однозначно лучше: нет просадок fps в 0, не было резких скачков fps вверх. Затем был словлен фриз на Centos 7.
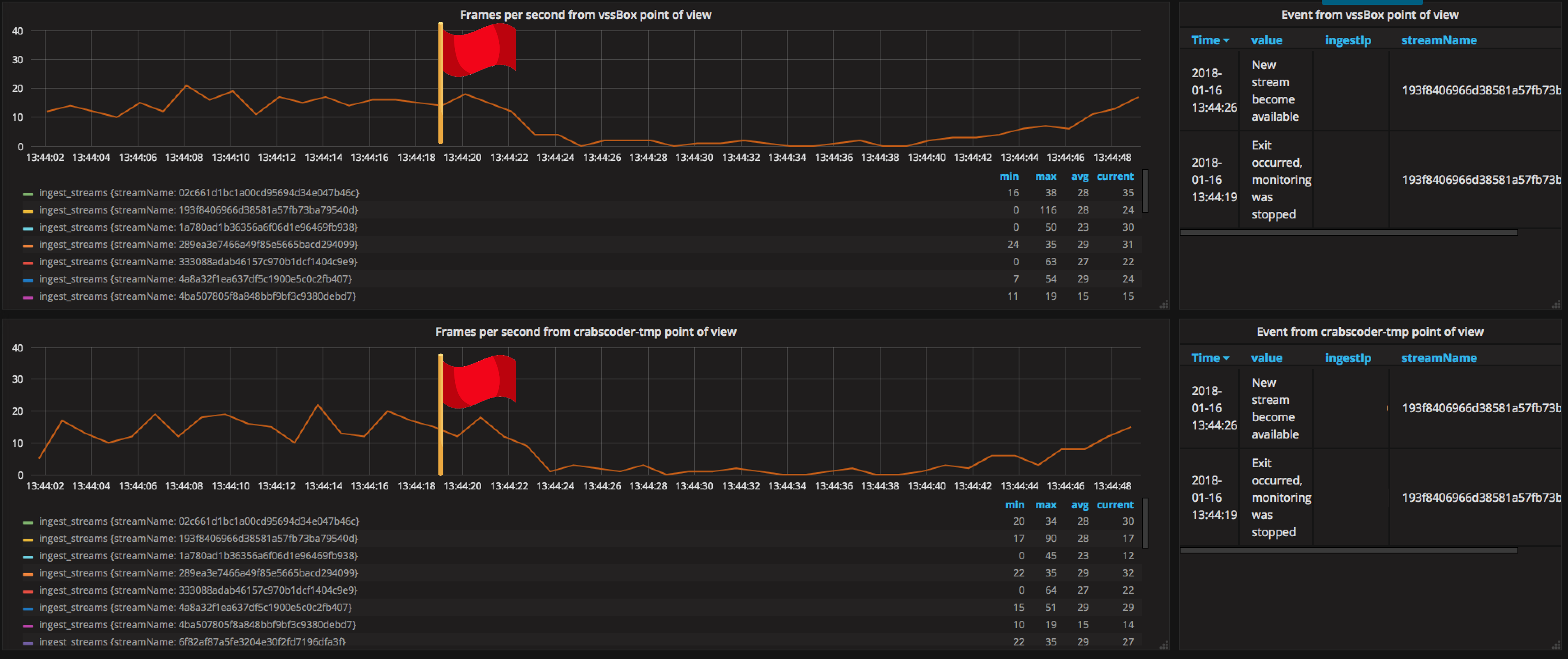
Флажком отмечен момент, когда на транскодере снова был замечен фриз. Только вот он не совпадает с моментом просадки fps, как считали ранее. Why?
Во время фризов и дропов некоторые потоки чувствовали себя хорошо и выглядели примерно как на графике ниже.
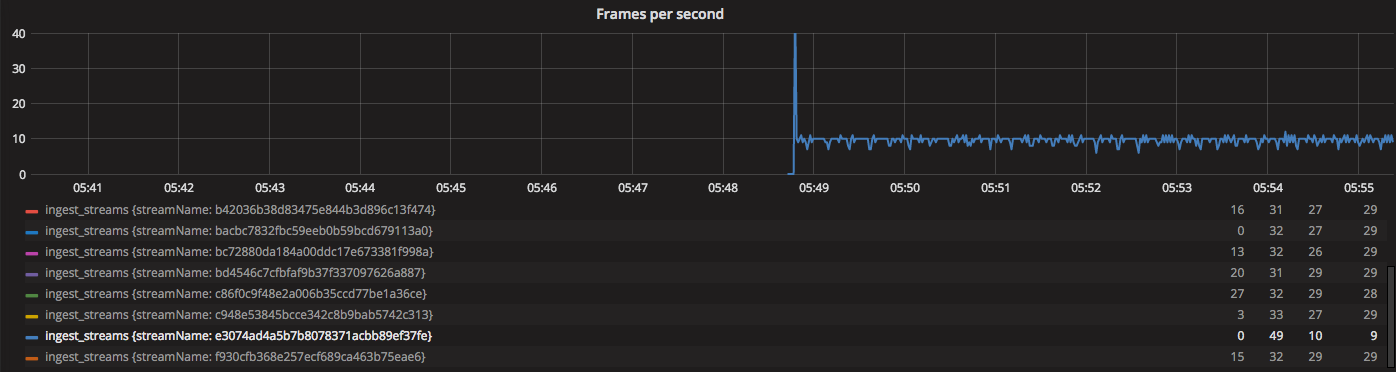
Но, судя по Kibana, эпизодический характер разрывов присутствует. Самое интересное, что он как внезапно начинается, так внезапно и заканчивается.
Продолжаются эксперименты с ядрами, дебаг и не дебаг, vzkernel и голое ядро, танцы, пляски, веселье.
Зашли в тупик. Остаётся пойти на шаг назад.
Всё началось с замеченных фризов и дропов потоков по SIGPIPE на стороне транскодера. Принято решение сделать шаг назад и вернуться к наблюдению самого транскодера. Транскодер работает на основе кодовой базы x264 и ffmpeg, потому:
- начинаем перехватывать трафик на транскодере (pcap) для дальнейшего анализа;
- раскручиваем debug level ffmpeg на маниакальный режим;
- релизим новый транскодер и начинаем ждать.
Внезапно, Chief Admin за какой-то надобностью начал по HTTP дергать Wowza на origin слое и удивился задержке ответа.
[[email protected] /]# time curl vss-w-o-3:1935
real 0m0.109s
user 0m0.003s
sys 0m0.001s
[[email protected] /]# time curl vss-w-o-3:1935
real 0m7.008s
user 0m0.003s
sys 0m0.001s
Сперва 100мс, а затем 7 секунд. Были замечены фризы и можно было анализировать логи с транскодеров.
Parsed protocol: 0
Parsed host : 10.2.1.174
Parsed app : origin
RTMP_Connect0, failed to connect socket. 4 (Interrupted system call)
rtmp://10.2.1.174/origin/117687be99efe796800e098e36b79f7e_bc2_hd: Unknown error occurred
[AVIOContext @ 0x18d9cc0] Statistics: 152844 bytes read, 0 seeks
RTMP_SendPacket: fd=5, size=34
Invoking deleteStream
Exiting normally, received signal 15.
video-quality-tools был прикручен в origin и стал виден настоящий
трэш.
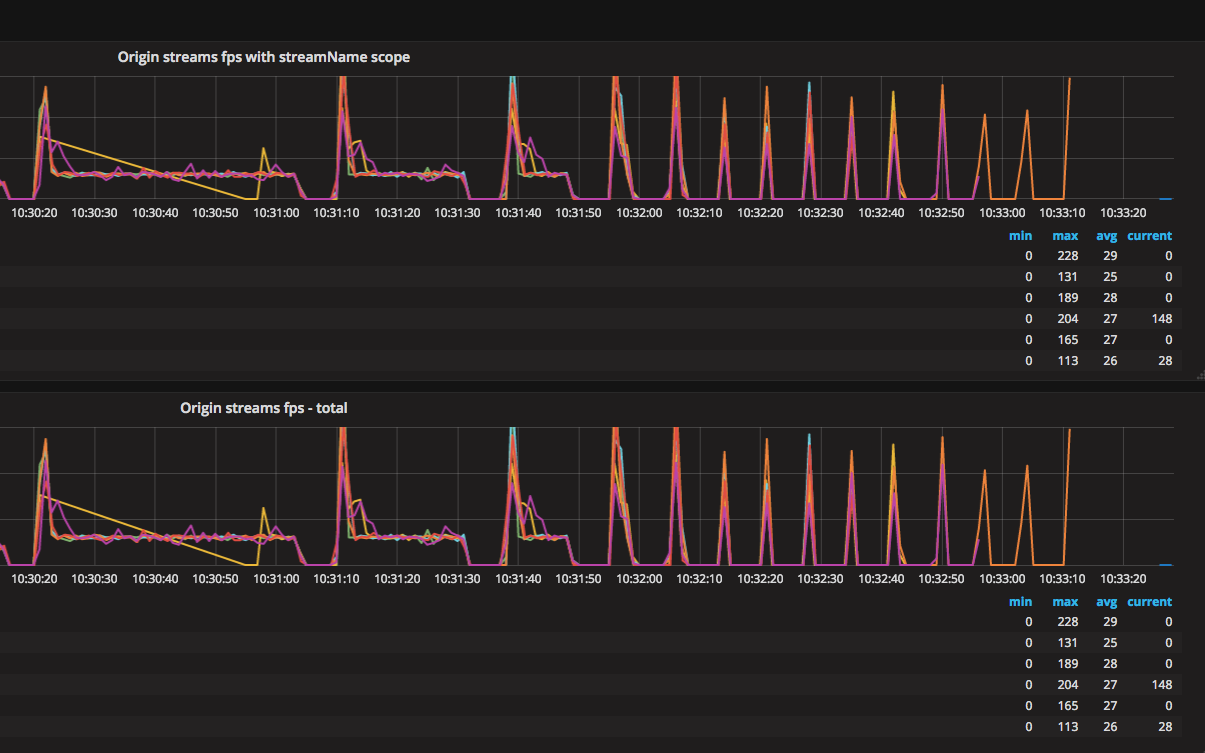
Чёрт, это же обрывы на стороне origin! Пазл моментально сложился:
- стало ясно, почему на графиках обрыв произошёл раньше, чем поток деградировал на ingest;
- SIGPIPE на транскодере возникали из-за origin;
- стало понятно, почему тюнинг Centos 7 не дал результат.
Переключив внимание на origin, попытались снять информацию strace, ведь perf требовал пересборки ядра и вынесения
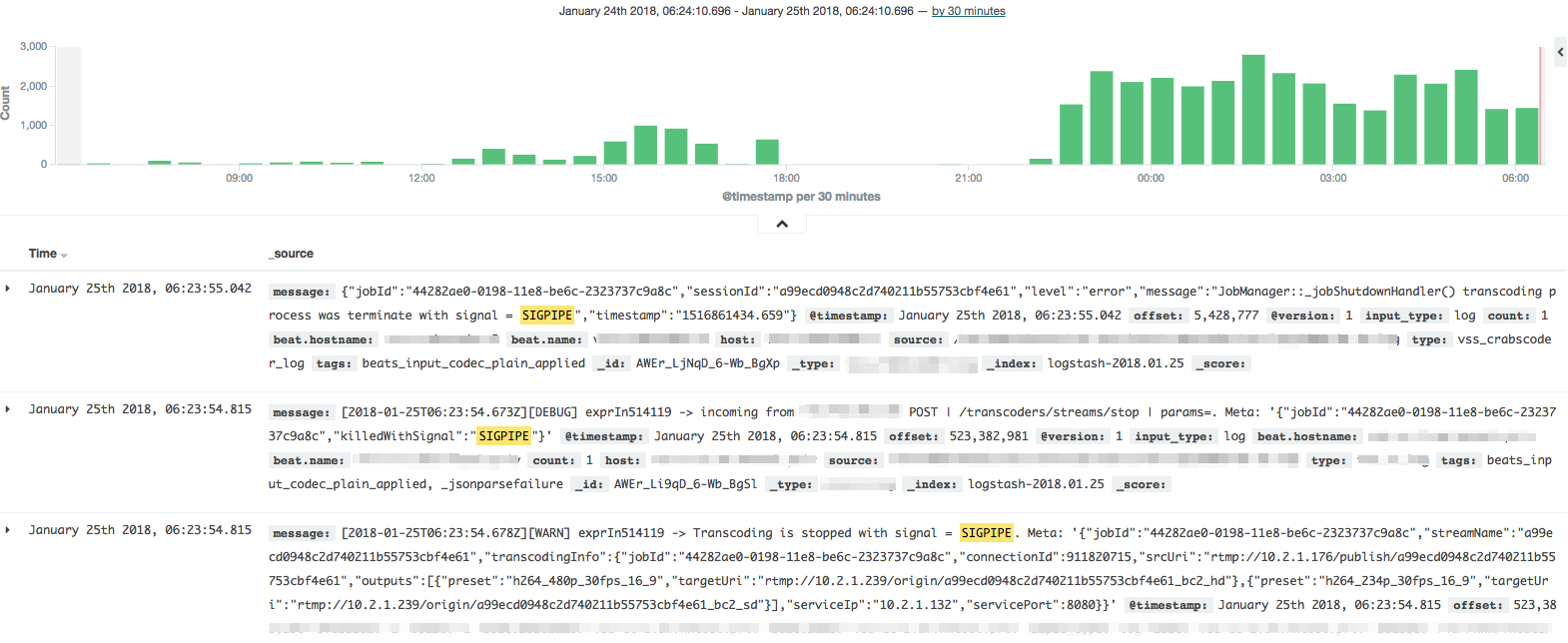
экспериментов на хардноду с виртуалки. strace нам не помог, ибо в моменты его запуска деградация начиналась
моментально: слишком большой негативный impact давал сам strace.
Вот как проявлялось включение strace.
Вся надежда оставалась на VisualVM. С его помощью можно профилировать Java приложения. Чтобы профайлер подключился, требуется перенастроить немного Wowza, подключиться к ней профайлером и работать… работать…
Отмечу, что одним из первых шагов при поиске проблемы на ingest, был запуск VisualVM. Ничего аномального не увидели и перешли к следующим шагам. Но на origin было всё иначе.
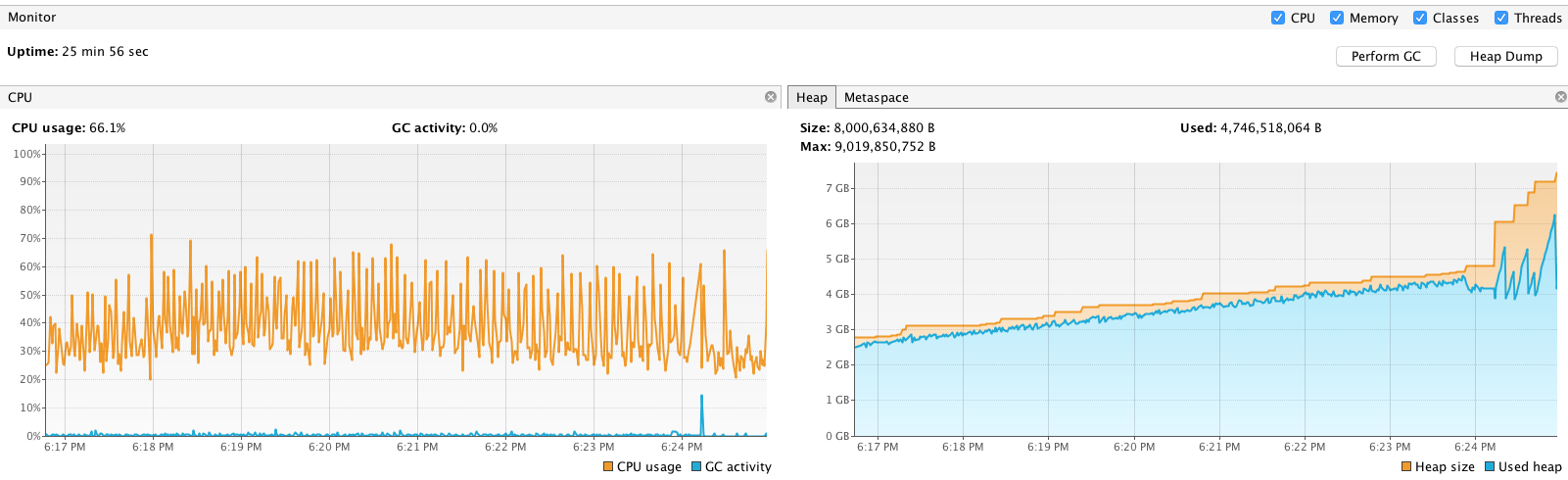
Видно, что с момента старта origin прошло всего 25 минут, но всё время плавала CPU утилизация и heap рос. В определённый момент времени он доходил до трешхолда и включался GC (garbage collector). Пока GC буйствовал, то происходил stop the world и всё замирало. Вот где была причина.
Мы использовали Wowza в продакшне несколько лет до этого, проводили нагрузочные тесты и получали нормальные результаты. Некоторые тесты днями гонялись на ней. Такого поведения ранее замечено не было. GC ранее не останавливал выполнение так часто, память так быстро не росла. Что-то не так с origin.
У Wowza реализованы MBeans, потому, наблюдая за разными переменными, установили причину роста потребления памяти.
Этой причиной оказались RTMP соединения от edge-серверов. При этом edge и origin были построены на базе Wowza!
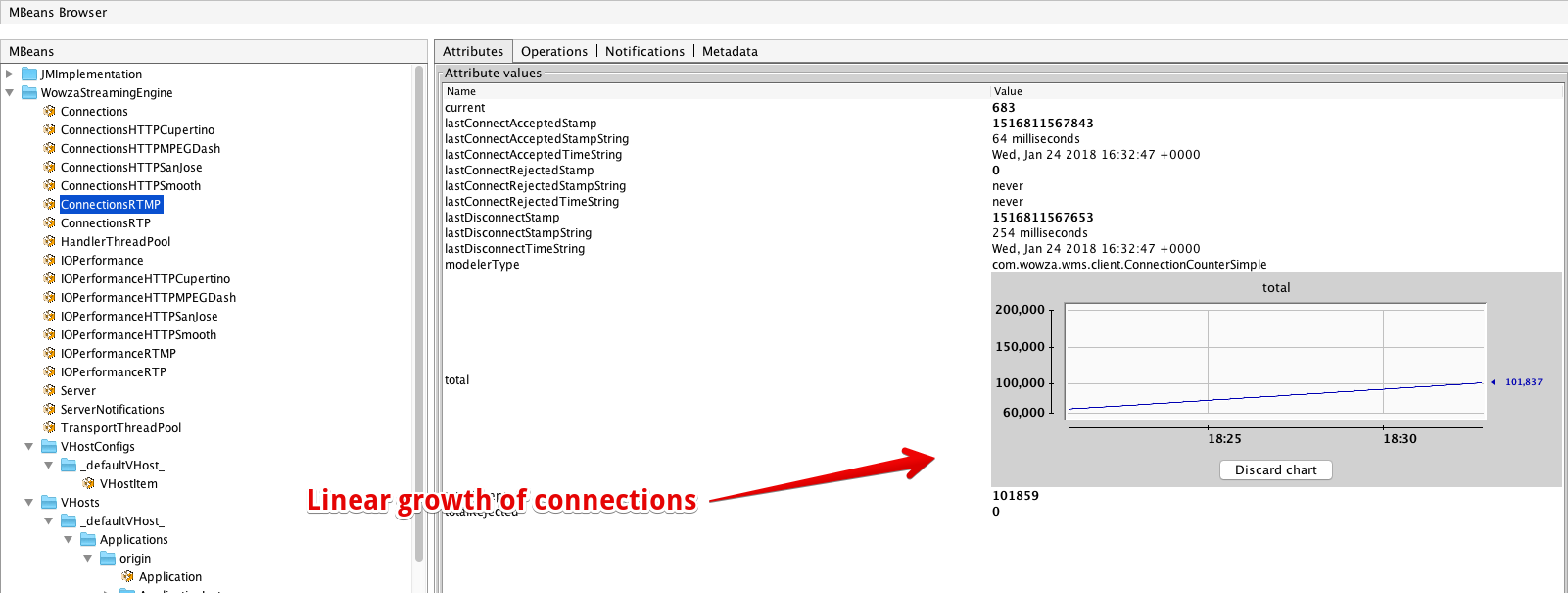
На изображении выше виден монотонный прирост RTMP соединений. Иногда за минуту могло прирости новых 50 соединений, и они сразу же закрывались. Но иногда Wowza-edge-сервера сходили с ума и Wowza начинала генерировать тысячи RTMP соединений на origin. Системы в этом особой не было.
С помощью tcpdump было установлено, что Wowza-edge пытался в цикле подключиться на origin, чтобы получить поток,
которого уже на origin нет. Бизнес логика заставляла забывать о таких потоках и не пытаться подключиться, но Wowza
игнорировала это, и всё равно подключалась и подключалась. Origin, что принимал на себя удар, устанавливал соединения,
обрабатывал запросы и отвечал, что потока нет, закрывая соединение… и сразу же ловил тысячи новых таких же запросов.
Когда поток соединений утихал, непонятно по какой причине, то всё устаканивалось и продолжало работать… до следующего шквала. Нагрузка так чётко распределилась, что наш мониторинг не заметил отклонений по CPU usage и мы не смотрели даже в сторону origin.
Посовещавшись и решив как действовать далее, учитывая прошлый опыт общения с саппортом, и поиски проблем, было решено:
- написать чудо-скрипт, выводящий на maintenance edge сервера с определённым интервалом;
- попробовать связаться с поддержкой Wowza;
- начать переписывать оставшуюся часть инфраструктуры.
Выбор для быстрого кандидата упал на nginx-rtmp-module. Это далеко не
идеальный кандидат для замены, модуль плохо работает с многопоточностью и лимитирует как объёмы трафика, так и количество
потоков, но это лучше чем ничего.
В бешеном темпе на изнеможение работали последний месяц для поиска проблемы, потому и переписывать 3 слоя системы пришлось тоже быстро и ударными темпами. Помогал тому выброс гормонов, и хотелось добить задачу. Решили сделать хакатон. Повод был и ранее, был неразрешённый вопрос в споре между стеком nodejs и golang. Дедлайн был установлен через 168 часов, ровно через 7 дней. Забегая вперед, скажу, что выиграл nodejs, но это уже другая история. Важно, что через неделю в продакшне уже крутился новый origin слой, без фризов и дропов потоков.
Забегая еще дальше, можно отметить, что проблема была всё время с момента существования Wowza, но не имела такого
выраженного эффекта. Как раз релиз в конце 2017 года позволил поднять качество остальных компонентов и сделать эту
проблему заметной. Тот же video-quality-tools стал для нас
лучшим индикатором происходящего в инфраструктуре.
Ретроспектива
Какие же можно сделать выводы из этой истории, сумасшедшей гонки на 40 дней?
Первое, что пришло в голову - не релизиться в преддверии праздников, выходных и массовых отпусков. Но, задумавшись, я не могу с уверенностью сказать, что это важная рекомендация. В процесс дебага и поиска решения я включился уже через 5-7 дней после релиза, потому взял удар на себя и провёл много бессонных ночей в поисках проблемы, погрузившись максимально глубоко. В тех обстоятельствах, прорелизившись хоть в феврале, мы бы столкнулись с проблемами. Список будет начинаться с другого пункта.
1. Готовить инструменты для поиска проблем заранее.
У нас не было поддержки perf на системе, не было опыта с perf в принципе и с strace на продакшне. Следовательно,
не было представления в какой мере strace оказывает негативное влияние. Flame graphs не использовали прежде.
2. Перед серьёзными релизами начинать собирать метрики до ввода в эксплуатацию подсистем и смотреть на изменения метрик.
Хоть и было множество метрик в zabbix, grafana и kibana, но их оказалось мало. Они все давали возможность
наблюдать за системой с bird eye view, но самое главное для нас (качество потока) мы начали замерять одновременно с
релизом. Потому мы не имели представления даже, как выглядело качество потоков до включения
video-quality-tools. Не с чем было сравнивать, потому, увидев плохие
графики, решили, что виноват не тот слой.
3. Я забрался слишком глубоко, дойдя до кода драйверов. Оглядываться стоит чаще.
Я где-то глубоко подсознательно понимал, что одни только настройки ОС, драйвера и ядро не может вносить такой сильный вклад. Это не стыковалось с данными, полученными за многие годы практического опыта, но я верил в silver bullet. Надо было вернуться к изучению транскодера, и это сэкономило бы несколько недель времени.
4. Повышать квалификацию команды и больше инвестировать в обучение.
Среди инженеров всё реже и реже можно встретить людей, которые понимают, как устроена операционная система под капотом, как работает сетевой стек, как устроены компьютеры и современные архитектуры. Это негативно влияет на скорость и качество разработки. Одна из целей данного материала состоит в стремлении показать другую сторону для инженеров, донести, что проблемы бывают сложные и неочевидные, что есть куда стремиться. Вместе с тем, я собрал много материала с которого можно начать и оттолкнутсья для расширения кругозора и практик. Для этой цели я веду телеграм канал “Об IT без галстуков” где пишу о технологиях, IT бизнесе, взгляде CTO на инженерные проблемы. Рад видеть новых подписчиков!
5. Это был невероятный опыт и неимоверный трип.
Хоть и было сложно мне и команде, но мы не сдались и преодолели этот пункт. Выражаю признательность и говорю спасибо всем, кто участвовал в поиске и устранении проблем. Каждый стал сильнее и опытнее. Помните, решение проблем - это всегда зона роста!
P.S. Финальный результат.
На данный момент система проработала стабильно полтора года, были ещё доработки, но жалоб не было. Некоторые партнёры после улучшений получили увеличение конверсии на +57%. Это непосредственно результат инженерных улучшений, видимый результат не всегда видимой работы. Мы продолжаем расти, ищем талантливых инженеров от linux администраторов, умеющих не только поднять k8s, до программистов на node, php, Java, c++. Главное - желание решать задачи и вдумчиво подходить к работе! Если после прочтения укрепилась вера в то, что на рынке бывают нужны не только frontend разработчики и magento архитекторы, то жду резюме в телеграме. Мои остальные контакты можно найти в футере блога!
А ещё, подписывайтесь на телеграм канал “Об IT без галстуков”, я там пишу о подобных вещах, ведении IT бизнеса, инженерном развитии, о менеджменте в IT.